这个报错是什么意思?要怎么解决?
问题遇到的现象和发生背景
问题代码的部分:
from lxml import etree
web='https://tieba.baidu.com/'
Selector=etree.HTML(web)
#提取属性——贴吧某网址
link=Selector.XPath('//head/script/@async src')
for i in link:
print(i)
报错内容:
File "c:/Users/Administrator.DESKTOP-MP1O82P/Desktop/py/scrach/Xpath-1.py", line 13, in
link=Selector.xpath('//head/script/@async src')
File "src\lxml\etree.pyx", line 1599, in lxml.etree._Element.xpath
File "src\lxml\xpath.pxi", line 305, in lxml.etree.XPathElementEvaluator.call
File "src\lxml\xpath.pxi", line 225, in lxml.etree._XPathEvaluatorBase._handle_result
lxml.etree.XPathEvalError: Invalid expression
PS C:\Users\Administrator.DESKTOP-MP1O82P>
你的Xpath不对,
按F12,选中需要提取的xpath,右键复制xpath,
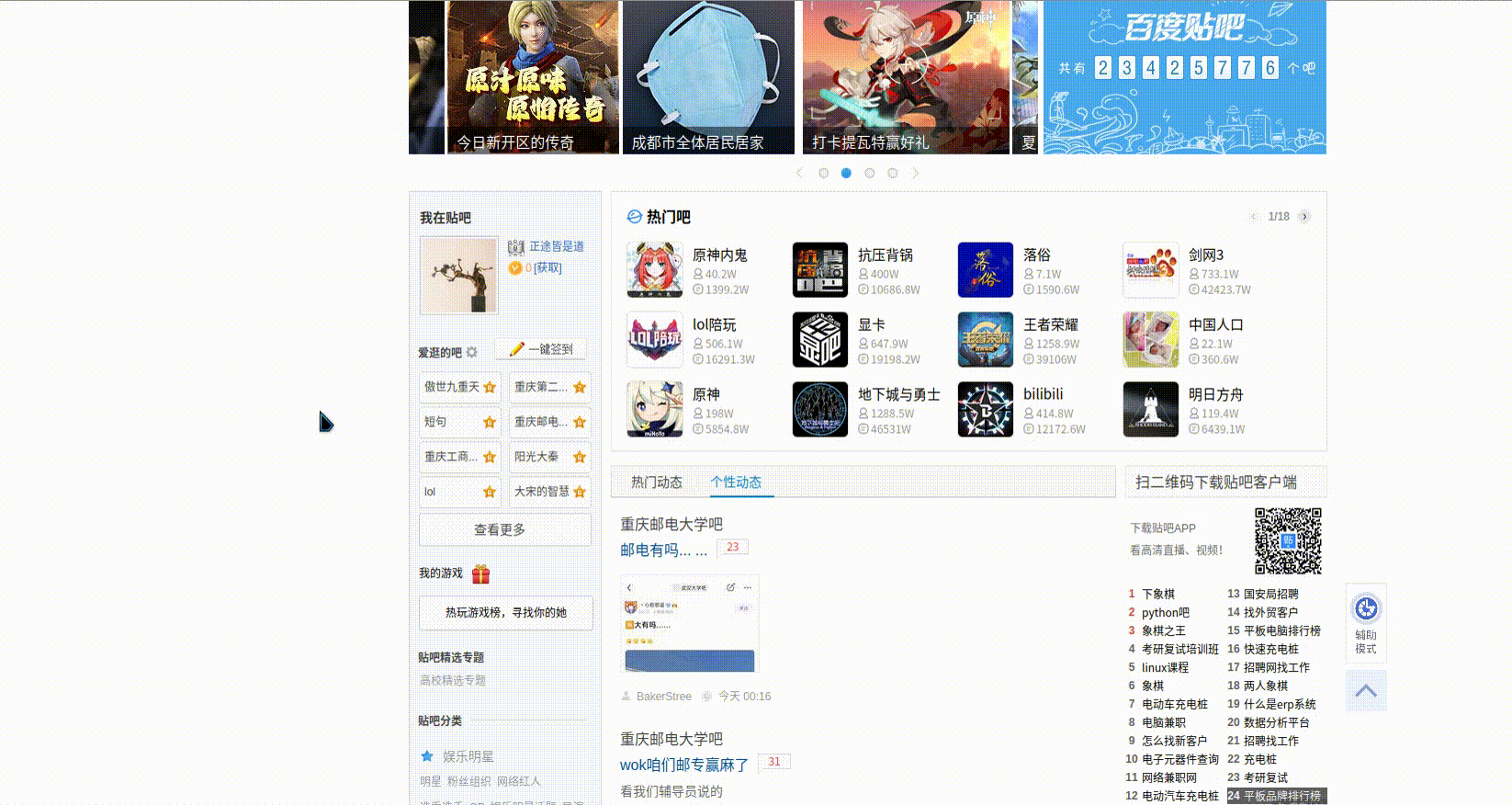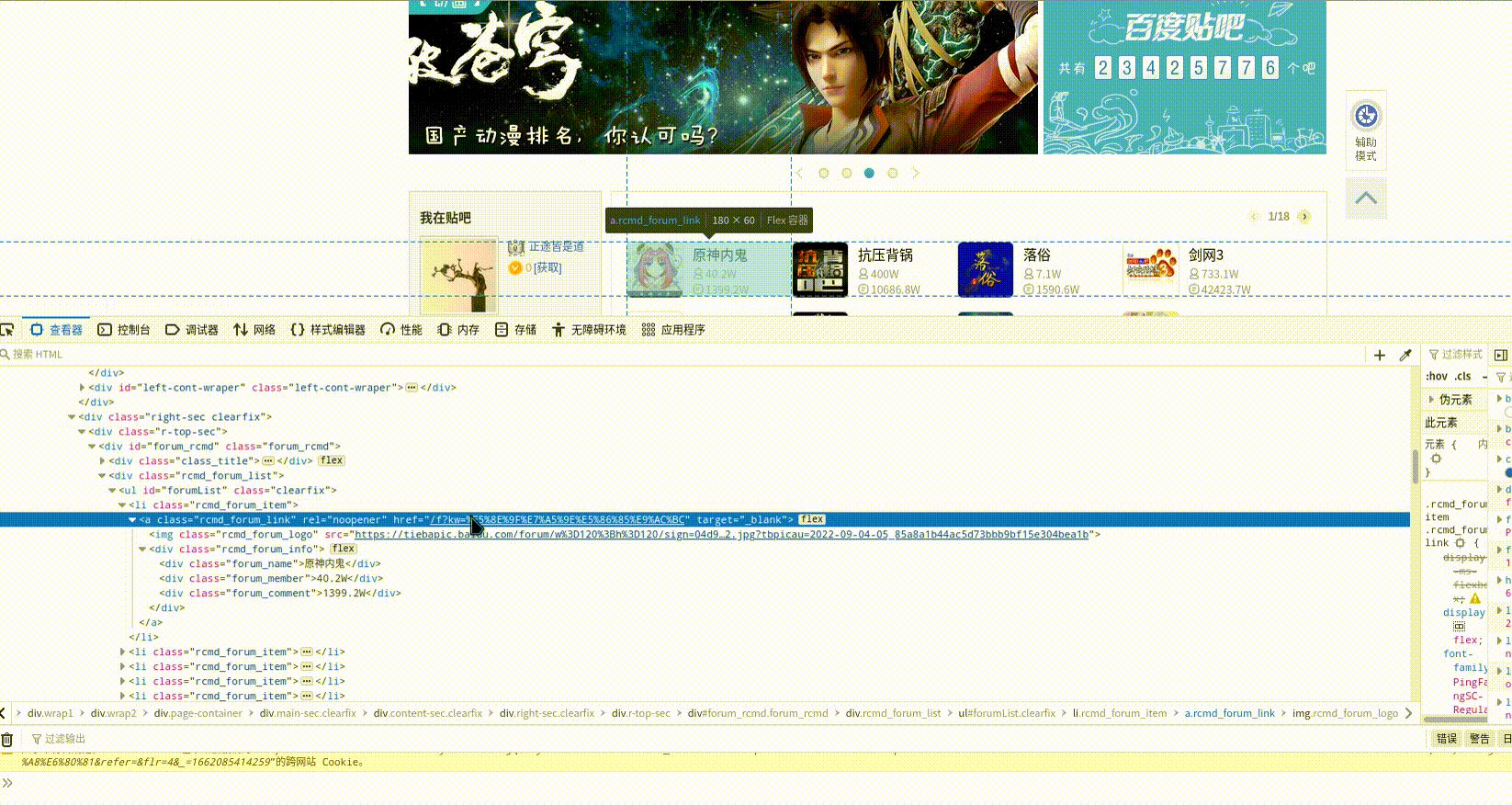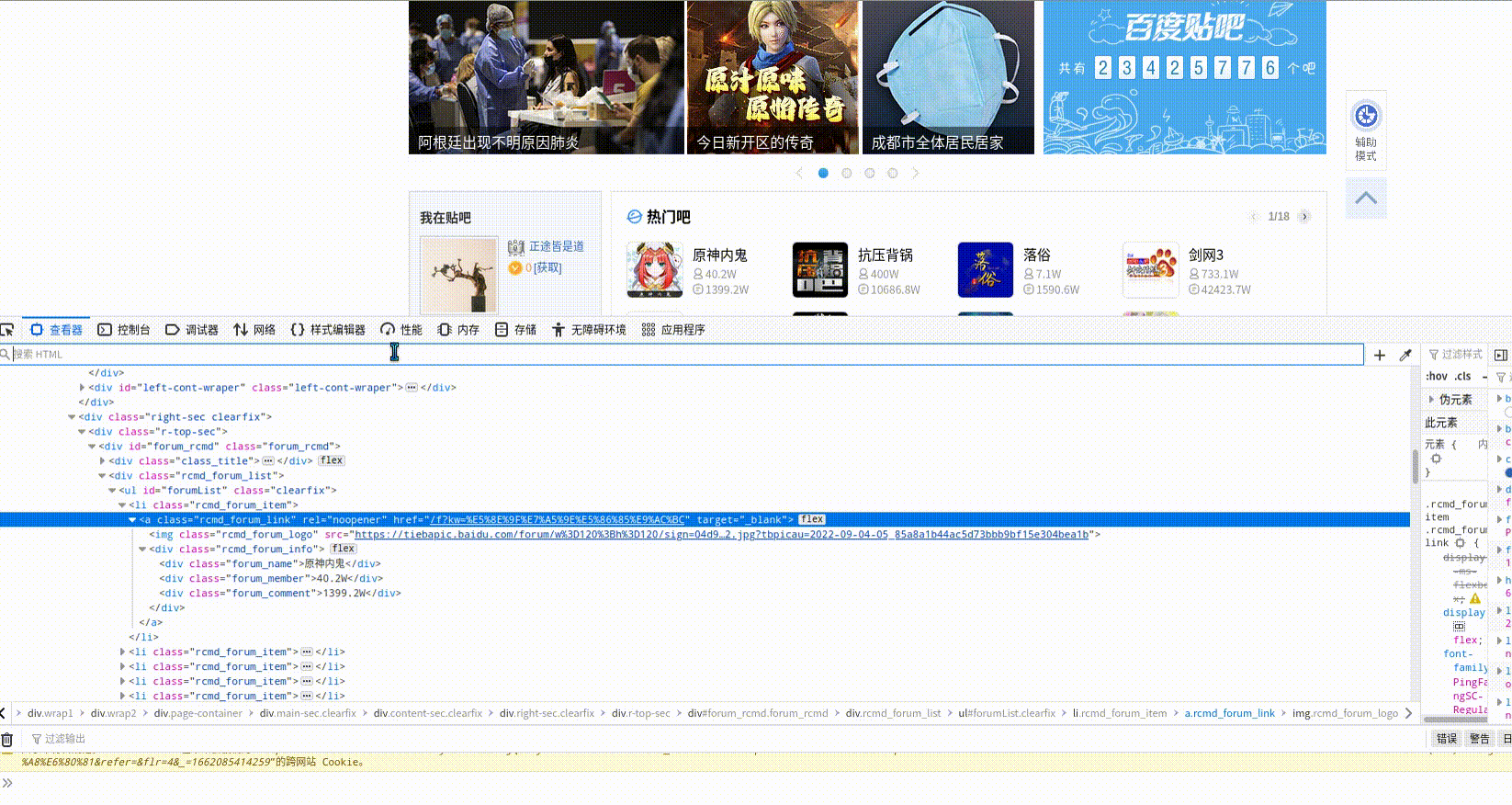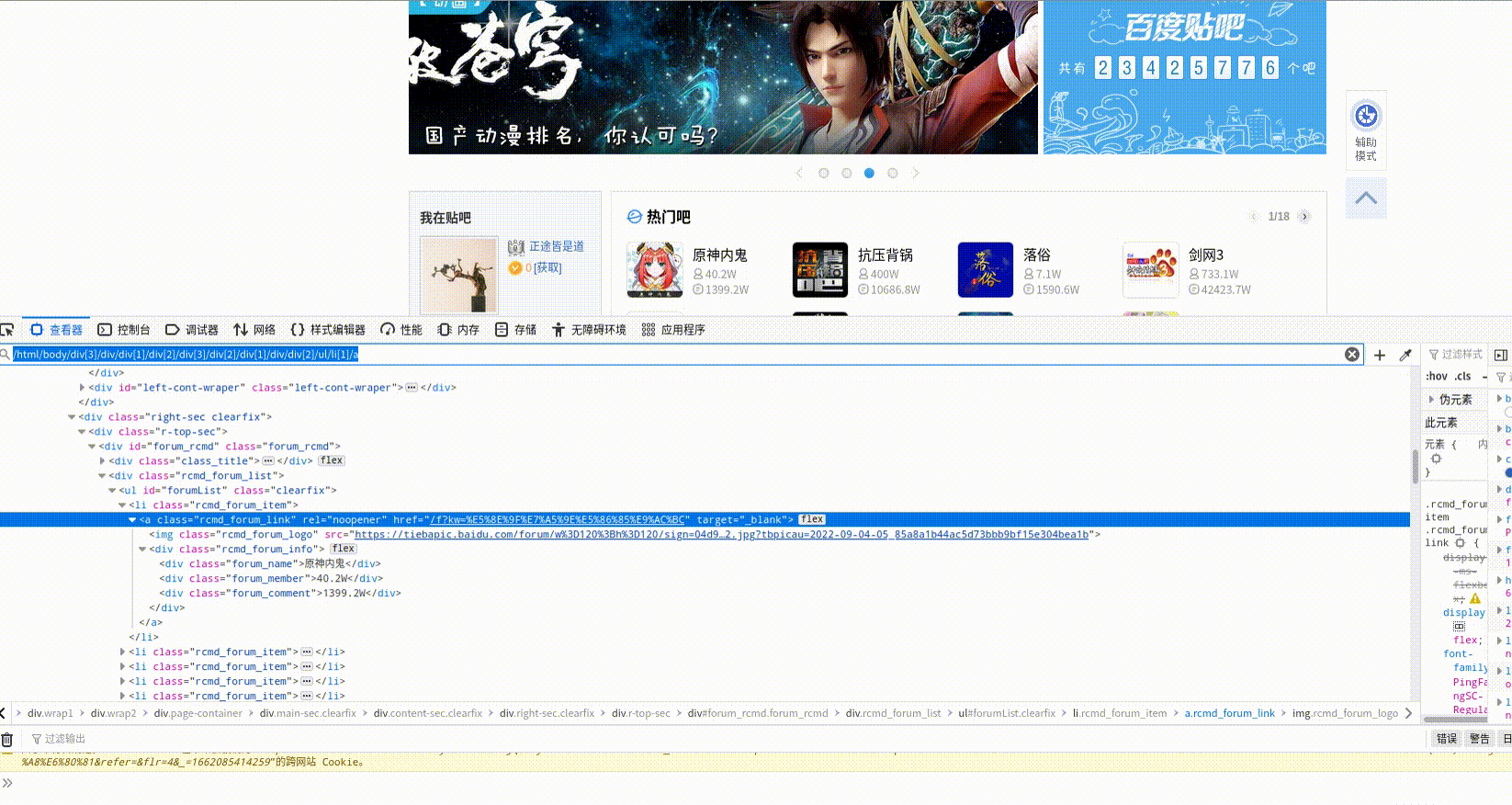
是这个路径吗?@async src?
//head/script/@async src 这个格式看看确定是否是这个样子的路径,这一行link=Selector.xpath('//head/script/@async src') 有问题