启动 Linux 上的 jupyter ,windows 浏览器打开地址登陆,编写pyspark程序报错
启动 Linux 上的 jupyter ,windows 浏览器打开地址登陆,编写pyspark程序:
## 准备数据
def preparJobdata(sc):
# 去取hdfs数据
rawUserData = sc.textFile("hdfs://master:9000/pydata/input/job.csv") #准备数据上传文件到hdfs
# 数据转换
jobitem = rawUserData.map(lambda line: line.strip().split(","))
# 岗位信息分词
rawRatings = rawUserData.map(splitJob)
# 将岗位信息特征依次封装
ratingsRDD = rawRatings.filter(lambda x: x[0] != '').map(lambda x: (x[0], x[1], x[2], x[3], x[4], x[5]))
return jobitem, ratingsRDD
jobitem, jobRDD = preparJobdata(sc)
jobitem.collect()
报错:
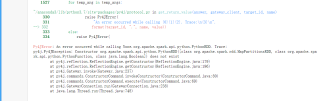
码友们求解~
报错每看懂,从代码上看splitJob没定义,splitJob是全局变量吗