Python代码未能实现目标功能
问题遇到的现象和发生背景
爬取网站股票数据后,进行数据排序,并以Excel格式将其存入指定文件夹 。
问题相关代码,请勿粘贴截图
import urllib.request
import re
import glob
import time
# 上海、深圳A股
allCodelist=[
'601099','601258','600010','600050','601668','601288','600604','600157','601519','600030',#上海A股
'000725','300059','002131','300116','002195','002526','002477','000536','300104','000793',#深圳A股
]
for code in allCodelist:
print('正在获取%s股票数据...' % code)
if (code[0] == '6' or code[0]=='9'):#A股
url = 'http://quotes.money.163.com/service/chddata.html?code=0' + code + \
'&start=20210701&end=20220819&fields=TCLOSE;HIGH;LOW;PCHG;VOTURNOVER'
print(url)
else:#B股
url = 'http://quotes.money.163.com/service/chddata.html?code=1' + code + \
'&start=20210701&end=20220819&fields=TCLOSE;HIGH;LOW;PCHG;VOTURNOVER'
print(url)
urllib.request.urlretrieve(url, 'd:\\S\\' + code + '.csv')#需要提前新建好D盘的“股票”目录,将数据写入csv文件
csvx_list = glob.glob('d:\\S\\*.csv')
print('总共发现%s个CSV文件' % len(csvx_list))
time.sleep(2)
print('正在处理............')
print('写入完毕!')
运行结果及报错内容
这个代码是根据网上资料修改的,目前可以将股票数据下载并存储为CSV文件。
我的解答思路和尝试过的方法
Python基础薄弱,正在学习。
我想要达到的结果
从网易财经下载的各支股票数据按照日期升序排列,以excel文件格式存贮到指定文件, 请帮忙将此代码修改完善 并实现目标功能。
完美解决之前有问题的代码。
已经修改更新了代码。
请验证。
# coding=utf-8
def sps():
ppath = 'D:/Dload' # 要存入数据的文件夹。
start = '20220801' # 要下载数据的起始日期。
# 上海、深圳A股股票代码列表。
codes = [
'601099', '601258', '600010', '600050', '601668', '601288', '600604', '600157', '601519', '600030', # 上海A股
'000725', '300059', '002131', '300116', '002195', '002526', '002476', '000536', '300101', '000793', # 深圳A股
]
return ppath, start, codes
def dload():
from urllib.request import urlretrieve
from os import makedirs, startfile
from pandas import read_csv
from datetime import date
from time import sleep
ppath, start, codes = sps()
makedirs(ppath, exist_ok=True)
end = date.today().strftime('%Y%m%d')
fin = [ppath, '/', '{}', '.xlsx']
fin = ''.join(fin).format
st0 = '正在下载第{:02}个股票{}的数据...'.format
urf = 'http://quotes.money.163.com/service/chddata.html?code={}{}&start={}&end={}' \
'&fields=TCLOSE;HIGH;LOW;PCHG;VOTURNOVER'.format('{}', '{}', start, end).format
fs = '10'
sh = '69'
for i, code in enumerate(sorted(codes), 1):
print(st0(i, code))
url = urf(fs[code[0] in sh], code)
fn = urlretrieve(url, fin(code))[0]
df = read_csv(fn, encoding='gbk')
df.sort_values('日期', inplace=True)
df.to_excel(fn, index=False)
print('已完成下载排序存入!')
sleep(1.0)
startfile(ppath)
return ppath
dl = dload()
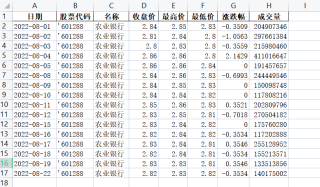
我有现成的,我帮你改下
下面代码可以解决你的问题,可能需要按照pandas包,装一下就好了:
import urllib.request
import pandas as pd
import glob
import time
# 上海、深圳A股
allCodelist = [
'601099', '601258', '600010', '600050', '601668', '601288', '600604', '600157', '601519', '600030', # 上海A股
'000725', '300059', '002131', '300116', '002195', '002526', '002477', '000536', '300104', '000793', # 深圳A股
]
for code in allCodelist:
print('正在获取%s股票数据...' % code)
if (code[0] == '6' or code[0] == '9'): # A股
url = 'http://quotes.money.163.com/service/chddata.html?code=0' + code + \
'&start=20210701&end=20220819&fields=TCLOSE;HIGH;LOW;PCHG;VOTURNOVER'
print(url)
else: # B股
url = 'http://quotes.money.163.com/service/chddata.html?code=1' + code + \
'&start=20210701&end=20220819&fields=TCLOSE;HIGH;LOW;PCHG;VOTURNOVER'
print(url)
file_name = 'd:\\S\\' + code + '.csv'
urllib.request.urlretrieve(url, file_name) # 需要提前新建好D盘的“股票”目录,将数据写入csv文件
# 读取文件数据
df = pd.read_csv(file_name, encoding='gbk')
# 按照列值排序
data = df.sort_values(by="日期", ascending=True)
# 把新的数据写入文件
data.to_excel('d:\\S\\' + code + '.xls')
csvx_list = glob.glob('d:\\S\\*.xls')
print('总共发现%s个EXCEL文件' % len(csvx_list))
time.sleep(2)
print('正在处理............')
print('写入完毕!')
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 22 10:00:27 2020
@author: LiKely
"""
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import time
import json
import xlwt
def get_list(url):
# 股票代码链接
res=requests.get(url)
res.encoding='utf-8'
# 完整HTML
html=BeautifulSoup(res.text,'html.parser')
# 股票代码列表
stockList=[]
for item in html.select('.stockTable a'):
try:
stockObj={}
stockObj['name']=item.text
stockObj['url']=item.get('href')
stockList.append(stockObj)
except:
print('出现异常')
return stockList
def get_detail(url):
# 股票链接
res=requests.get(url)
res.encoding='utf-8'
# 完整HTML
html=BeautifulSoup(res.text,'html.parser')
# 股票对象
result={}
result['title']=''
result['code']=''
result['state']=''
result['nowtime']=''
result['url']=''
result['maxheight']=''
result['minheight']=''
result['childTitles']=[]
result['childValues']=[]
try:
# 股票名称
result['title']=html.select('.stock_title h1')[0].text
except:
print('读取股票名称,出现异常',url)
try:
# 股票代码
result['code']=html.select('.stock_title h2')[0].text
except:
print('读取股票代码,出现异常',url)
try:
# 股票状态
result['state']=html.select('.stock_title em')[0].text
except:
print('读取股票状态,出现异常',url)
try:
# 当前时间
result['nowtime']=html.select('.stock_title time')[0].text
except:
print('读取当前时间,出现异常',url)
try:
# 股票链接
result['url']=url
except:
print('读取股票链接,出现异常',url)
try:
# 最高
result['maxheight']=html.select('.s_height dd')[0].text
except:
print('读取最高,出现异常',url)
try:
# 最低
result['minheight']=html.select('.s_height dd')[1].text
except:
print('读取最低,出现异常',url)
try:
# 股票各项指数标题
childTitles=[]
for item in html.select('.s_date dt'):
childTitles.append(item.text)
result['childTitles']=childTitles
except:
print('读取股票各项指数值,出现异常',url)
try:
# 股票各项指数值
childValues=[]
for item in html.select('.s_date dd'):
childValues.append(item.text)
result['childValues']=childValues
except:
print('读取股票各项指数值,出现异常',url)
return result
if __name__ == "__main__": #主函数
# 获取股票代码列表
stockList=get_list('https://hq.gucheng.com/gpdmylb.html')
# 获取股票各项指数标题列表
firstChildTitleList=get_detail(stockList[0]['url'])['childTitles']
print('获取到'+str(len(stockList))+'个股票代码')
# 创建工作簿
book = xlwt.Workbook(encoding='utf-8')
# 创建工作表
sheet = book.add_sheet('股票代码')
# 创建固定表头
head = ['股票名称','股票代码','状态','时间','网址','最高','最低']
for h in range(len(head)):
sheet.write(0,h,head[h])
#追加各项指标表头
for h in range(len(firstChildTitleList)):
sheet.write(0,len(head)+int(h),firstChildTitleList[h])
# 写入固定列数据
for i,item in enumerate(stockList):
try:
stockObj=get_detail(item['url'])
sheet.write(i+1,0,stockObj['title'])
sheet.write(i+1,1,stockObj['code'])
sheet.write(i+1,2,stockObj['state'])
sheet.write(i+1,3,stockObj['nowtime'])
sheet.write(i+1,4,stockObj['url'])
sheet.write(i+1,5,stockObj['maxheight'])
sheet.write(i+1,6,stockObj['minheight'])
# 写入各项指标列数据
for j,child in enumerate(stockObj['childValues']):
sheet.write(i+1,7+j,child)
print (str(i),'写入成功')
# print (str(i),'写入成功',stockObj)
except:
print (str(i),'出现异常',stockObj['url'])
book.save('股票代码.xls')
print('写入完毕!>>股票代码.xls')
1.获取所有stockcode
2.创建数据库STOCK,用于存储行情数据
3.以“s_代码”在数据库STOCK中创建/添加数据表,用于存储个股的历史行情数据
4. 遍历各表,读取各表最后一条记录中的开盘日期;输入实际最新开盘日期;两日期比对,若日期为空则表为空 故下载该股全部历史数据,若日期不同,则表中数据非当前最新行情数据,故更新数据至实际最新开盘日期;若日期相同,则表明表中数据已是最新数据,故跳过。
5.将个票的历史行情数据对应存储到各表