关于python爬虫遇到的问题
2问题遇到的现象和发生背景
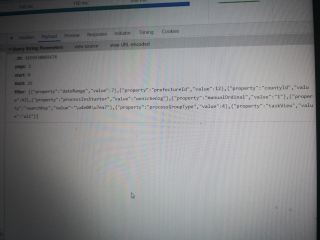
类型:该网页的URL是拼接的, 请求方式是get,pyload提交是json数据
如下是头请求的数据:
Request URL: http://网址隐藏:7413/api/entity/task?_dc=1659430069176&page=1&start=0&limit=25&filter=%5B%7B%22property%22%3A%22dateRange%22%2C%22value%22%3A7%7D%2C%7B%22property%22%3A%22prefectureId%22%2C%22value%22%3A12%7D%2C%7B%22property%22%3A%22countyId%22%2C%22value%22%3A43%7D%2C%7B%22property%22%3A%22processInsStarter%22%2C%22value%22%3A%22wenzchenzg%22%7D%2C%7B%22property%22%3A%22manualOrdinal%22%2C%22value%22%3A%221%22%7D%2C%7B%22property%22%3A%22searchKey%22%2C%22value%22%3A%22%5Cu4e00%5Cu7ea7%22%7D%2C%7B%22property%22%3A%22processGroupType%22%2C%22value%22%3A4%7D%2C%7B%22property%22%3A%22taskView%22%2C%22value%22%3A%22all%22%7D%5D
Request Method: GET
Status Code: 200
Content-Type: application/json
下面是payload的参数:
_dc: 1659430069176
page: 1
start: 0
limit: 25
filter: [{"property":"dateRange","value":7},{"property":"prefectureId","value":12},{"property":"countyId","value":43},{"property":"processInsStarter","value":"wenzchenzg"},{"property":"manualOrdinal","value":"1"},{"property":"searchKey","value":"\u4e00\u7ea7"},{"property":"processGroupType","value":4},{"property":"taskView","value":"all"}]
然后把payload的都传参进requests.get,但是一直读不到数据,报错
3问题相关代码,请勿粘贴截图
import requests
import json
import pprint
import time
from urllib.parse import urlencode
p = str(int(time.time() * 1000))
url = "网址隐藏:7413/api/entity/task"
cookie = "cookie隐藏"
headers = {
"Connection": "keep-alive",
"Content-Type": "application/json",
"Cookie": cookie,
"Host": "网址隐藏:7413",
"Referer": "网址隐藏:7413/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36",
}
data = {
"_dc": p,
"page": 1,
"start": 0,
"limit": 200,
"filter": [{"property":"dateRange","value":7},
{"property":"prefectureId","value":12},
{"property":"countyId","value":43},
{"property":"processInsStarter","value":"wenzchenzg"},
{"property":"manualOrdinal","value":"1"},
{"property":"searchKey","value":"\u4e00\u7ea7"},
{"property":"processGroupType","value":4},
{"property":"taskView","value":"all"}]
}
re = requests.get(url=url,headers=headers,data=json.dumps(data)).json()
pprint.pprint(re)
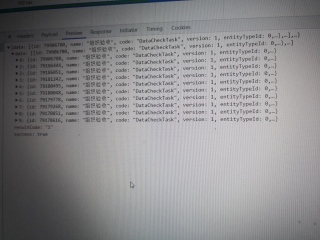
4运行结果及报错内容
{'resultCode': '0',
'resultDetailText': 'java.lang.NullPointerException\n',
'resultText': 'java.lang.NullPointerException',
'success': True}
5我的解答思路和尝试过的方法
第一次请求出错后,感觉是不是url的问题,然后用
urlcode把ULR都参数拼接后请求拼接的URL,但是还是没用
6我想要达到的结果
请求能够得到数据
把data=json.dumps(data)改成data=data看看
urlencode之后,正确的话除了_dc和你上面的url就是一样的,不一样就换一下编码方式。
import string
from urllib.parse import urlencode
data = urlencode(data, encoding='UTF-8', safe=string.printable)
#urlencode拼接后也一样报错
data = urlencode(data)
re = requests.get(url=url,headers=headers,data=json.dumps(data)).json()
pprint.pprint(re)
#也试了下url拼接参数拼接,也报错
data = urlencode(data)
url = url + "?" + data
re = requests.get(url=url,headers=headers,data=json.dumps(data)).json()
pprint.pprint(re)
data = urlencode(data)
re = requests.get(url=url,headers=headers,data=data )
这样呢,
这种应该是某个参数没有设置正确,可以参照以下步骤:
- 页面找到该请求,右键复制-->以cULR格式复制
- 到https://spidertools.cn/#/curl2Request网址粘贴进行转换
- 复制转换后的代码进行请求试一下看能不能成功
我看你那里是get请求,应该是params=data,看看页面上data还是params,
如果全部书写都是正确的,就不要纠结什么data,或者dumps(data)
有可能就是被反扒了,反爬也没看见你所给出的是什么参数反爬,有可能是cookies反爬等等