PYTHON requests 爬虫数据请求返回空。
问题遇到的现象和发生背景
用PYTHON 的 requests库请求一个post 状态码是200,但是返回内容是空。但同样的数据在fiddler 组合器,或者其它请求调试器中反回来JOSN。
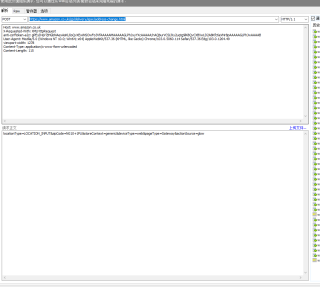
得到的结果

另一个
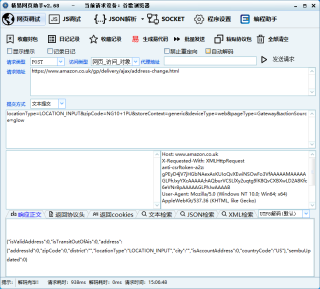
网页上找的都可以
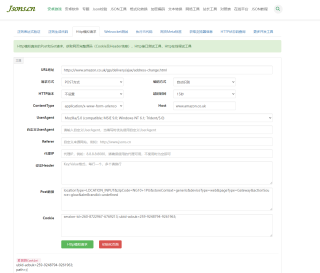
https://www.amazon.co.uk/gp/delivery/ajax/address-change.html
post
Host: www.amazon.co.uk
X-Requested-With: XMLHttpRequest
anti-csrftoken-a2z: gPEyD4jV7jHGbNAexAsKUIoQvXEwiNSOwFo3VfAAAAAMAAAAAGLPhJxyYXcAAAAA;hAQburVCSLlXy2uqtg9lK8QvCXBXwLD2A8Kfc6eVNr8pAAAAAGLPhJwAAAAB
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49
Content-Length: 115
locationType=LOCATION_INPUT&zipCode=NG10+1PU&storeContext=generic&deviceType=web&pageType=Gateway&actionSource=glow
问题相关代码,请勿粘贴截图
import requests
import json
url = 'https://www.amazon.co.uk/gp/delivery/ajax/address-change.html'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49',
'viewport-width': '1278',
'Host': 'www.amazon.co.uk',
'Connection': 'keep-alive',
'X-Requested-With': 'XMLHttpRequest',
'anti-csrftoken-a2z': 'gPEyD4jV7jHGbNAexAsKUIoQvXEwiNSOwFo3VfAAAAAMAAAAAGLPhJxyYXcAAAAA;hAQburVCSLlXy2uqtg9lK8QvCXBXwLD2A8Kfc6eVNr8pAAAAAGLPhJwAAAAB',
'Content-Type': 'application/x-www-form-urlencoded',
}
data = {
'locationType': 'LOCATION_INPUT',
'zipCode': 'NG10 1PU',
'storeContext': 'generic',
'deviceType': 'web',
'pageType': 'Gateway',
'actionSource': 'glow',
'almBrandId': 'undefined'
}
zip_code = requests.post(url=url, headers=header, data=data)
print(zip_code.text)
print(zip_code.cookies)
运行结果及报错内容

我想要达到的结果
得到这个空的JOSN数据
body中的参数是用urlencoded形式传过去的
import requests
from urllib.parse import urlencode
import requests
from urllib.parse import urlencode
url = 'https://www.amazon.co.uk/gp/delivery/ajax/address-change.html'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49',
'viewport-width': '1278',
'Host': 'www.amazon.co.uk',
'Connection': 'keep-alive',
'X-Requested-With': 'XMLHttpRequest',
'anti-csrftoken-a2z': 'gPEyD4jV7jHGbNAexAsKUIoQvXEwiNSOwFo3VfAAAAAMAAAAAGLPhJxyYXcAAAAA;hAQburVCSLlXy2uqtg9lK8QvCXBXwLD2A8Kfc6eVNr8pAAAAAGLPhJwAAAAB',
'Content-Type': 'application/x-www-form-urlencoded'
}
data = {
'locationType': 'LOCATION_INPUT',
'zipCode': 'NG10 1PU',
'storeContext': 'generic',
'deviceType': 'web',
'pageType': 'Gateway',
'actionSource': 'glow',
'almBrandId': 'undefined'
}
post_data = urlencode(data)
zip_code = requests.post(url=url, data= post_data, headers=header)
print(zip_code.text)
你这访问的是个html页面,怎么可能返回json格式的数据呀。
你这页面浏览器打开也是空页面

会不会是被限制爬了,然后针对你的请求就返回空值了,换个IP试试,或者重启下猫
如果是企业使用的话,建议使用代理IP试试
举个例子,比如我们百度查询天气
import urllib.request,re
keywd = '天气'
keywd = urllib.request.quote(keywd) #中文时需转换
url = 'http://www.baidu.com/s?wd='+keywd
data = urllib.request.urlopen(url).read().decode("utf-8")
pat = "title:'(.*?)',"
rst = re.compile(pat).findall(data)
print(rst)
结果:

解决办法:添加对应的浏览器版本信息;(注意! ! ! 不要用最新版本的;我在测试时使用最新浏览器的版本号,也是返回空)
import urllib.request,re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/82.0.4051.0 Safari/537.36 Edg/82.0.425.0'}
keywd = '天气'
keywd = urllib.request.quote(keywd) #中文时需转换
url = 'http://www.baidu.com/s?wd='+keywd
data = urllib.request.urlopen(url).read().decode("utf-8")
pat = "title:'(.*?)',"
rst = re.compile(pat).findall(data)
print(rst)
结果返回就正常了

希望可以帮到你
一般都是参数漏了,抓包对比一下
你爬的方法不对,这是动态
缺少User-Agent请求头
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/82.0.4051.0 Safari/537.36 Edg/82.0.425.0'
这是动态数据来的,方法用错了
爬取所用方法不对吧,考虑换种方法试试