如何使用Pandas解决下述问题?
问题遇到的现象和发生背景
在最近的需求开发中,针对原有逻辑进行开发,导出的Excel数据如下所示:
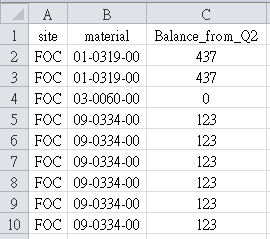
提示: 以上数据仅为Demo数据,其中site和material分组后,如果两者数值分为同一组别,字段'Balance_from_Q2'数值是相同的,不存在数值不相等的情况
问题: 客户对字段'Balance_from_Q2'数据显示提出要求,根据字段'site'和'material'分组,只对分组后第一行显示数据,其余的行设置为空(NaN)
问题相关代码,请勿粘贴截图
import pandas as pd
df = pd.DataFrame({'sit':['FOC', 'FOC', 'FOC', 'FOC', 'FOC','FOC','FOC','FOC','FOC'],
'material':['01-0319-00','01-0319-00','03-0060-00','09-0334-00','09-0334-00','09-0334-00','09-0334-00','09-0334-00','09-0334-00'],
'Balance_from_Q2':[437,437,0,123,123,123,123,123,123]})
我想要达到的结果
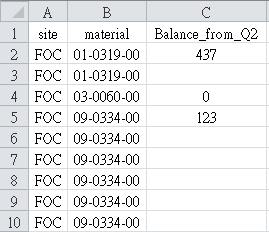
你想要的结果可能要在你上一步之上处理,你可以参考一下去重的方法,或者说分组聚合取第一条结果,希望对你有所帮助