seleium学习爬虫技术遇到的问题
问题遇到的现象和发生背景
现在在学习网络爬虫技术,在学习seleium的实践的题目,爬取评论的特定信息。
本来是按照指导书籍的步骤写下去的,但不知道为啥报错
问题相关代码,请勿粘贴截图
from selenium import webdriver
driver=webdriver.Firefox(executable_path=r"C:\网络下载专区\geckodriver-v0.31.0-win64\geckodriver.exe")
driver.get("http://www.santostang.com/2018/07/04/hello-world/")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title=’livere‘]"))
comment=driver.find_element_by_css_selector("div,reply-content")
content=comment.find_element_by_tag_name("p")
print(content.text)
运行结果及报错内容
报错行:driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title=’livere‘]"))
selenium.common.exceptions.NoSuchElementException: Message: Unable to locate element: iframe[title=’livere‘]
我的解答思路和尝试过的方法
感觉是iframe后面得标签错了,其实也不太清楚。
我想要达到的结果
第一次接触自己写的代码也不明所以,希望能指出报错的地方,帮忙解释一下。
你"iframe[title=’livere‘]"中单引号(')写成了中文全角的,要改成英文半角的。
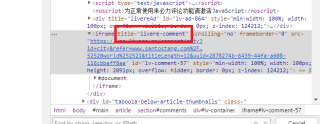
并且你页面中没有title='livere'的iframe
只有title='livere-comment'的iframe
所以应该是
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere-comment']"))
可能是人家页面代码改了,你爬虫代码也要跟着修改
定位元素失败,可以网址中的源码改了,没有title属性为livere的iframe标签了,你可以改成获取其他标签,没必要完全照着敲代码
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632