vscode调试js加密代码

爬取url:https://finance.sina.com.cn/realstock/company/sh600835/nc.shtml
要求
js调试文件和怎么找到加密数据的截几张步骤
说明图,一起压缩发到这个邮箱,这个邮箱是yx13235480522@163.com
我估计你是理解错了,你需要的数据并不需要解密js,现在给一个解决方案,你可以直接用:
基本思路是:csv文件不存在则创建带表头的csv文件,然后读取成dadaframe数据,通过接口读取你需要的数据,解析后存到dadaframe中,其中我增加了时间判断,只有在开盘时间段内读取的数据才会存起来,如果时间过了下午3点,则停止程序,如果要读取多天数据,可以在第二天9点前再运行程序,数据格式参考表头设计。
import requests
import execjs
import pandas as pd
import os
import time
import numpy as np
from datetime import datetime as dt
filename = 'shjd.csv' #定义存储文件名称,建议每个时间段存为不同的名称,后期再合并,可以防止数据丢失
if not os.path.exists(filename): #判断文件是否存在,不存在则创建
#创建df文件,添加表头
df = pd.DataFrame(columns=['时间','成交价',
'卖⑤(成交价)', '卖⑤(成交量)',
'卖④(成交价)', '卖③(成交量)',
'卖③(成交价)', '卖②(成交量)',
'卖②(成交价)', '卖①(成交量)',
'卖①(成交价)', '卖①(成交量)',
'买⑤(成交价)', '买⑤(成交量)',
'买④(成交价)', '买④(成交量)',
'买③(成交价)', '买③(成交量)',
'买②(成交价)', '买②(成交量)',
'买①(成交价)', '买①(成交量)'])
df.index.name = '序号' #指定索引列名称
df.to_csv(filename,encoding='GBK') #保存csv文件
df = pd.read_csv(filename,index_col='序号',encoding='GBK') #读取csv文件
index = df.index #读取索引
codes = "sh600835,sh600835_i,sh900925,RMBUSD,bk_new_jtys" #股票代码
headers = {'referer': 'http://finance.sina.com.cn'} #设置请求头
t = time.time() #计算当前时间
try:
while True:
resp = requests.get('http://hq.sinajs.cn/list=' + codes, headers=headers, timeout=6) #发送请求,获取数据
data = resp.text #取返回数据的内容
docjs = execjs.compile(data) #用execjs编译返回的js代码
res = docjs.eval('hq_str_sh600835') #取js代码中的hq_str_sh600835变量数据
infos = res.split(',') #分割数据
datetime = infos[-4]+' '+infos[-3] #取时间数据组成数据时间
#判断当前时间是否开盘
if dt.strptime(infos[-4]+' 09:00:00', '%Y-%m-%d %H:%M:%S')<dt.now()<dt.strptime(infos[-4]+' 11:30:00', '%Y-%m-%d %H:%M:%S') or dt.strptime(infos[-4]+' 13:00:00', '%Y-%m-%d %H:%M:%S')<dt.now()<dt.strptime(infos[-4]+' 15:00:00', '%Y-%m-%d %H:%M:%S'):
data = infos[-24:-4] #取买卖数据
data = data[::-1] #反序
data = [round(float(data[i]), 2) if i%2==0 else int(data[i])//100 for i in range(len(data))] #成交价保留两位小数,成交数量除以100
row = np.hstack(([datetime, round(float(infos[7]),2)],data)) #把时间,成交数据,以及买卖数据组成一个数组
df.loc[df.iloc[:,0].size] = row #在df数据中添加一行
if time.time()-t>600: #每隔10分钟存一次数据
df.to_csv(filename,encoding='GBK')
t = time.time()
time.sleep(3) #等待3秒
if dt.now()>dt.strptime(infos[-4]+' 15:00:00', '%Y-%m-%d %H:%M:%S'): #如果时间到了下午15点以后,存储数据,并停止程序
df.to_csv(filename,encoding='GBK')
break
except: #如果中途停止程序或者程序出错,保存当前数据
df.to_csv(filename,encoding='GBK')
# 从字符串中匹配出目标
def get_array(string: str):
string = string.split('\n')[0]
wait_arr = string.split(',')
title_arr = ['卖⑤', '卖④', '卖③', '卖②', '卖①', '成交', '买①', '买②', '买③', '买④', '买⑤', ]
target_arr1 = [wait_arr[-5], wait_arr[-7], wait_arr[-9], wait_arr[-11], wait_arr[-13], wait_arr[7], wait_arr[11],
wait_arr[13], wait_arr[15], wait_arr[17], wait_arr[19]]
for i in range(len(target_arr1)):
target_arr1[i] = round(eval(target_arr1[i]), 2)
target_arr2 = [wait_arr[-6], wait_arr[-8], wait_arr[-10], wait_arr[-12], wait_arr[-14], None, wait_arr[10],
wait_arr[12], wait_arr[14], wait_arr[16], wait_arr[18]]
for i in range(len(target_arr2)):
if target_arr2[i] is None:
continue
target_arr2[i] = eval(target_arr2[i]) // 100
# print(title_arr)
# print(target_arr1)
# print(target_arr2)
for k, v, z in zip(title_arr, target_arr1, target_arr2):
print(k, '\t', v, '\t', z)
return title_arr, target_arr1, target_arr2
st = """var hq_str_sh600835="上海机电,12.880,12.720,13.190,13.210,12.600,13.180,13.190,4319985,56335025.000,66200,13.180,11900,13.170,16700,13.160,200,13.150,11300,13.140,68900,13.190,75000,13.200,10600,13.210,35800,13.220,13300,13.230,2022-06-20,15:00:03,00,";
var hq_str_sh600835_i="A,shjd,0.7900,0.7084,0.1600,12.2037,109.7358,102273.9308,80650.43,80650.43,21623.5008,CNY,8.1092,7.2451,5.5000,1,1.3400,39.5704,1.6565,16.790,10.620,0.1,上海机电,X|O|0|0|0,13.99|11.45,20220331|165646612.99,671.2000|85.5050,|,,1/1,EQA,,2.46,15.92|12.2|12.72,专用设备";
"""
get_array(st)
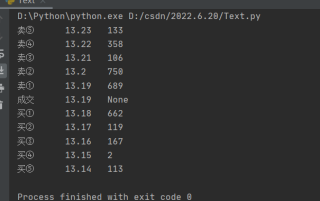
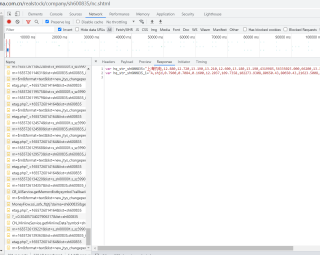
没加密吧,就是在返回的js里面的特定位置而已,不过这个请求的数据包邮一个_参数,应该是时间戳经过处理的