只有二十几行!对于各位很简单,求解!
刚刚学习python,代码不报错,但是没有输出结果,不知道为什么,求大家喵一眼!就二十多行代码!
代码如下
import requests
from bs4 import BeautifulSoup
url="http://news.qq.com/"
请求腾讯新闻的URL,获取其text文本
wbdata=requests.get(url).text
对获取到的文本进行解析
soup=BeautifulSoup(wbdata,'lxml')
从解析文件中通过select选择器定位指定的元素,返回一个列表
news_titles=soup.select("div.text > em.f14 > a.linkto")
对返回的列表进行遍历
for n in news_titles:
title=n.get_text()
link=n.get("href")
data={ '标题':title, '链接':link}
print(data)
这个网站是一个动态的数据加载的, 你想要获取更多的新闻内容, 链接以及标题, 可以看xhr里面的数据
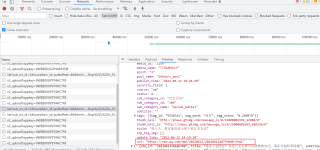
具体实现的代码如下
import requests
url = 'https://i.news.qq.com/trpc.qqnews_web.kv_srv.kv_srv_http_proxy/list'
data = {
'sub_srv_id': '24hours',
'srv_id': 'pc',
'offset': '60',
'limit': '20',
'strategy': '1',
'ext': '{"pool":["top"],"is_filter":7,"check_type":true}',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'
}
response = requests.get(url=url, params=data, headers=headers)
# print(response.json())
for index in response.json()['data']['list']:
dit = {
'标题': index['title'],
'发布名': index['media_name'],
'分类': index['sub_category_cn'],
'发布日期': index['publish_time'],
'链接': index['url'],
}
print(dit)
运行效果

因为你的news_titles是空的,循环根本没走
你不要老想一步到位
在前面放个print,把中间结果打印出来
看一步一步的是不是符合你的预期,再调整
抓取不成功,是因为news_titles是空的,
而news_titles是空的原因是原来的页面是要运行很多js后才能真正呈现出内容,而你当前只是抓取了最原始的html内容部分,所有的script都没有加载执行。
解决办法:
引入selenium模块,用真实浏览器驱动来获取可以加载脚本的页面,再获取。例如:
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
url="http://news.qq.com/"
opts = Options()
opts.add_argument('--headless') # 设置为无头浏览器,方便在一些没有图形界面环境下也能加载
driver = webdriver.Chrome(options=opts)
driver.get(url=url)
sleep(5) # 一般等待页面加载完成,可以调大这时数据以保证数据加载完整
soup=BeautifulSoup(driver.page_source, 'lxml')
news_titles=soup.select("div.detail a.lunbo") # 你选取的特征好像抓不到内容,我调整了下
for n in news_titles:
title=n.get_text()
link=n.get("href")
data={ '标题':title, '链接':link}
print(data)
你的select匹配应该有问题, sorry我才发现不能把数据贴出来,提示内容过长,下面是我跑的代码:
import requests
from bs4 import BeautifulSoup
url=r'https://news.qq.com/'
data=requests.get(url)
print(data)
soup=BeautifulSoup(data.text,'html.parser')
print(soup)
soup里面没有你要的select