为什么我爬取的内容是乱码
import requests
from lxml import etree
url="https://www.haodf.com/doctor/list.html%22
head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/86.0.4240.198 Safari/537.36"}
f=open('大夫.csv','w',encoding='gb18030')
f.writelines('姓名,职位,单位,科室,疗效,态度,擅长,在线问诊,预约挂号\n')
def getdata(url):
res=requests.get(url,headers=head)
res.encoding='utf-8'
print(res.status_code)
html=res.text
res.encoding=res.apparent_encoding
htmlele = etree.HTML(html)
姓名
name=htmlele.xpath('/html/body/div[2]/div/div[1]/div[2]/ul/li[*]/div/div/p[1]/span[1]/a/text()')
print(name)
职位
zhiwei=htmlele.xpath('/html/body/div[2]/div/div[1]/div[2]/ul/li[*]/div/div/p[1]/span[2]/text()')
print(zhiwei)
#单位
address=htmlele.xpath('/html/body/div[2]/div/div[1]/div[2]/ul/li[*]/div/div/p[2]/text()')
print(address)
#科室
keshi=htmlele.xpath('/html/body/div[2]/div/div[1]/div[2]/ul/li[*]/div/div/p[2]/span/text()')
print(keshi)
#疗效
good=htmlele.xpath('/html/body/div[2]/div/div[1]/div[2]/ul/li[*]/div/div/div/p[1]/span[3]')
print(good)
#态度:
servers=htmlele.xpath('/html/body/div[2]/div/div[1]/div[2]/ul/li[*]/div/div/div/p[2]/span[3]')
print(servers)
#擅长
nice=htmlele.xpath('/html/body/div[2]/div/div[1]/div[2]/ul/li[*]/div/div/p[3]/text()')
print(nice)
#在线问诊
money=htmlele.xpath('/html/body/div[2]/div/div[1]/div[2]/ul/li[*]/div/div/span[1]/span')
print(money)
#预约挂号
telephone=htmlele.xpath('/html/body/div[2]/div/div[1]/div[2]/ul/li[*]/div/div/span[2]/span')
print(telephone)
for i in range(0,10):
url = 'https://www.haodf.com/doctor/list.html?p=%27+str(i)
getdata(url)
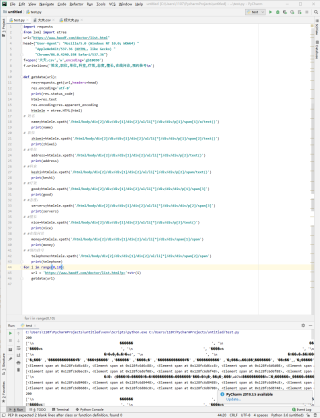
这行去掉就行了
res.encoding='utf-8'
encoding改成gbk 或者 gb2313呢?