写了爬虫百度贴吧的python代码,一直报错,求解决?
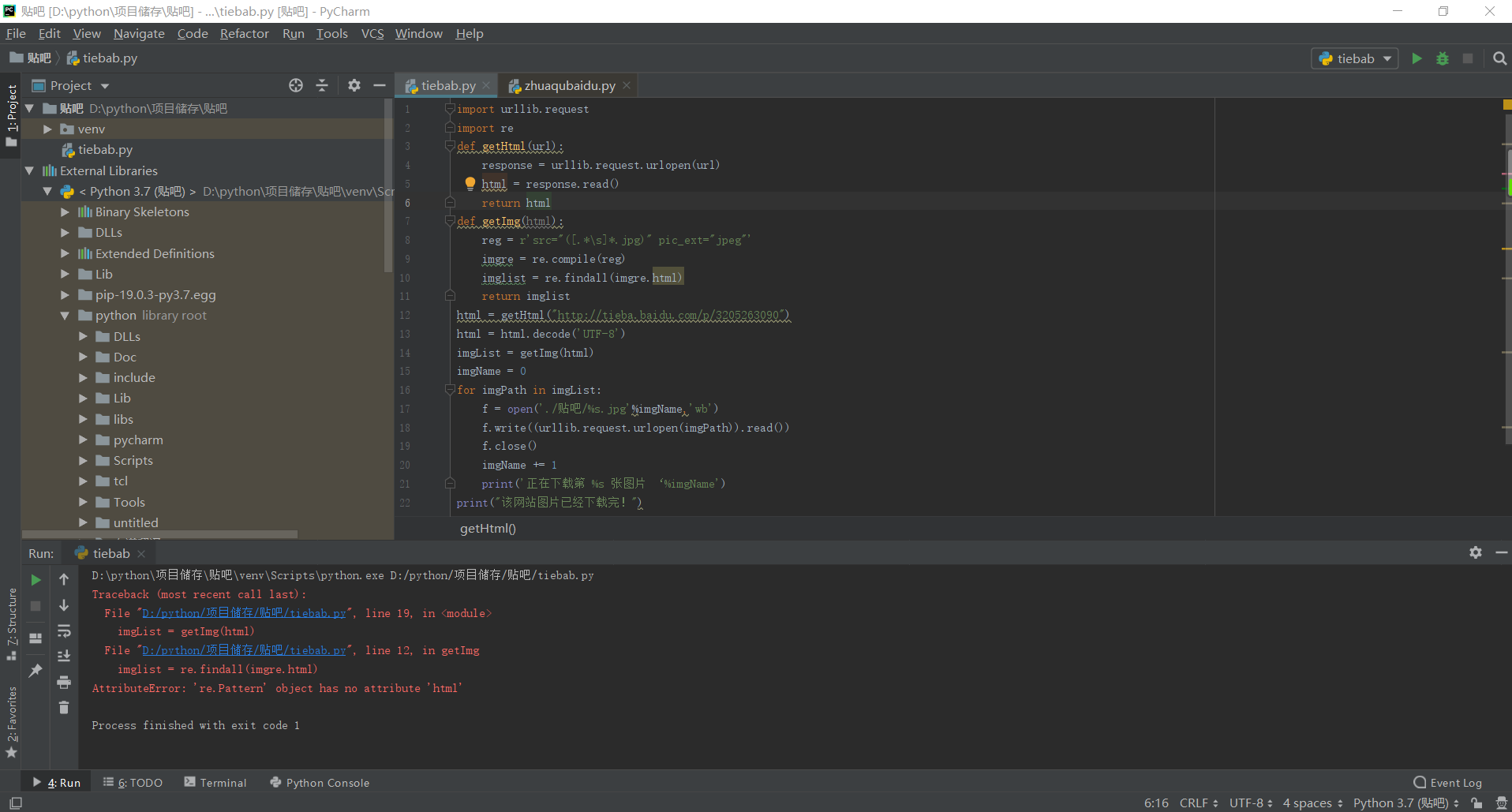
写了爬虫百度贴吧的python代码,一直报错,求解决
改过这个imglist = re.findall(imgre.html)为imglist = imgre.findall(html)
确实不报错,但是输出有问题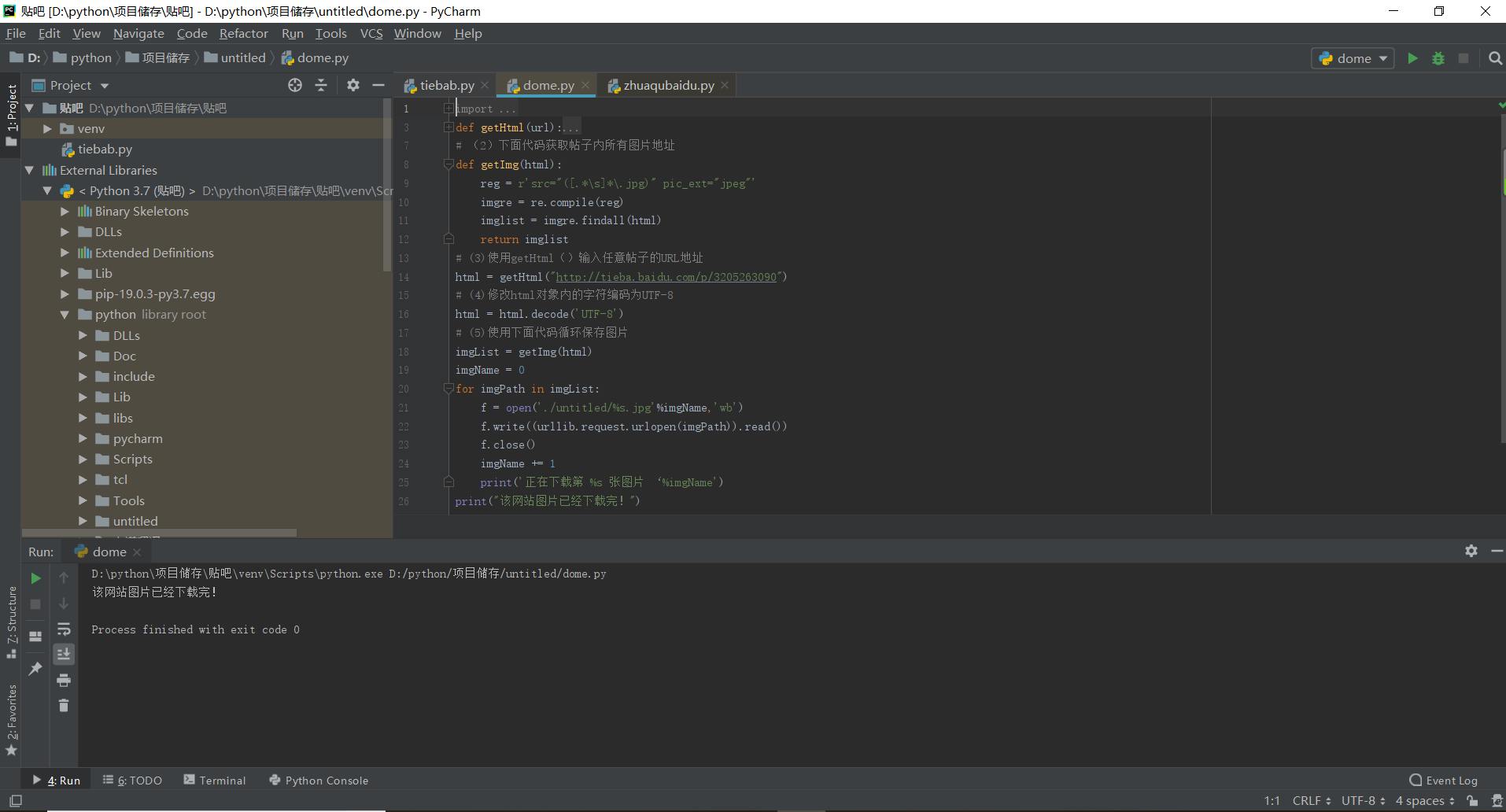
第一个报错是因为正则 re.compile 返回的对象没有 html 属性,只有 findAll 、search 等方法。
第二个可能是正则没有匹配上内容。
把图换成代码贴出来测测。
第一张图,应该是逗号隔开,不是点,改成下面这样:
imglist = re.findall(imgre, html)
第二张图,倒数第二个print,格式化输出有点问题,改成下面这样:
print('正在下载第 %s 张图片' % imgName)
试一下看看有没有问题。
getImg方法有问题 正则匹配到的为空,返回的事空列表[]