Python网络构建中节点的数据统计
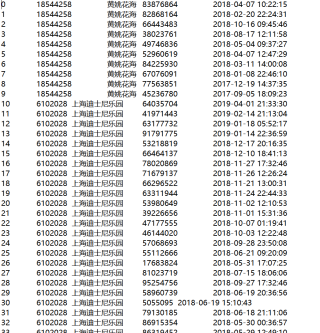

图里的数据,我有一百多万行,第一列,就是序号,按1到一百多万排的,第二列,是景点ID,就是第三列里,景点名称对应的数字代号吧算,第四列,是来到过这个景点的人的代码,一组数字代表一个游客,也有很多重复的,第五列是人去景点地旅游的时间,
现在问题有
1.根据景点ID(也就是第二列)统计景点数量
2.统计各个景点的用户访问量,就是第四列里有多少个人来过同一个景点
3.统计用户数量(就是第四列里出现过对少组不同的数字代码)
4.统计各个用户访问的景点数量
然后我现在可以用Python导出第二列和第四列然后去重,也就是1和3大概可以解决掉,2和4怎么解决
因为数据太多,可能计算机内存会是一个问题,所以就说一下解题思路吧
假设把数据全部读取进来,存成一个字典数组,那么代码可以这么写:
其中r1、r3是1和3的解,r2和r4是2和4的解的子集
lst = [{'key1':'value1','key2':'value2','key3':'value3','key4':'value4','key5':'value5'},{},{},{}]
r1 = set([l['key2'] for l in lst])
r3 = set([l['key4'] for l in lst])
for r in r1:
r2 = set([l['key4'] for l in lst if l['key2']==r])
for r in r3:
r4 = set([l['key2'] for l in lst if l['key4']==r])