仿照hamlet.txt的方式,按照分词方式(jieba分词)对threeking.doms.txt进行词频统计,并输出词频最高的20个词及词频

如图所示,程序内提取附件是with open('threekingdoms.txt','r',encoding='utf-8')as f :
print(f.read())
说明:代码是使用我自己的数据进行实现的,使用时要把你数据文件的路径传给变量dic_path
请采纳,谢谢!
(1)
代码如下:
import jieba
dic_path = './10.txt' # 文件的路径
with open(dic_path, 'r', encoding='utf8') as f:
txt = f.read()
print(txt)
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word) == 1: #排除单个字符的分词结果
continue
else:
counts[word] = counts.get(word,0) + 1 # 统计词频
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True) # 按词频进行降序
for i in range(20): # 打印词频前20 的词
word, count=items[i]
print("{0:<10}{1:>5}".format(word, count))
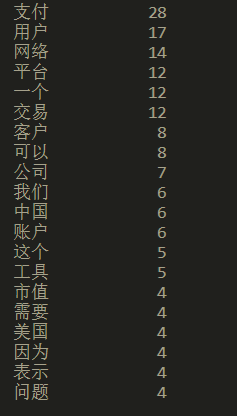
结果:
(2)代码如下:
import jieba
dic_path = './10.txt'
with open(dic_path, 'r', encoding='utf8') as f:
txt = f.read()
print(txt)
words=jieba.lcut(txt)
counts={}
# fu和text分别存储标点符号和转义字符,若统计词频出现时可以在这里添加来洗去
fu = '[·’!"\#$%&\'()#!()*+,-./:;<=>?%%^@!\@,:?¥★、—_….>【】[]《》?“”‘’\[\\]^_`{|}~]+。'
text = ['\u3000','\n']
for word in words:
if len(word) != 1: #排除单个字符的分词结果
continue
elif word in fu: # 去除标点符号
continue
elif word in text: # 去转义字符
continue
else:
counts[word] = counts.get(word,0) + 1 # 统计词频
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True) # 按词频进行降序
# print(items)
for i in range(20):
word, count=items[i]
print("{0:<10}{1:>5}".format(word, count))
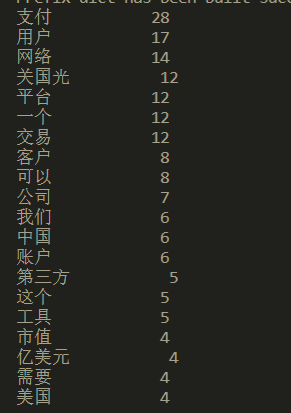
结果如下:
(3)代码如下:
import jieba
dic_path = './10.txt'
with open(dic_path, 'r', encoding='utf8') as f:
txt = f.read()
print(txt)
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word) != 2: #排除单个字符的分词结果
continue
else:
counts[word] = counts.get(word,0) + 1 # 统计词频
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True) # 按词频进行降序
for i in range(20):
word, count=items[i]
print("{0:<10}{1:>5}".format(word, count))
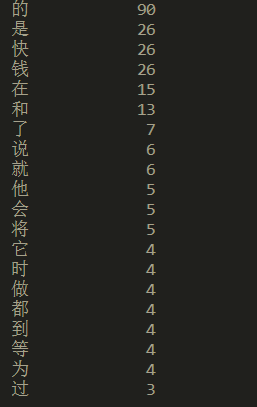
结果: