Python: 'NoneType' object has no attribute 'string'
爬个网文试手,开始用的soup.select()能正常爬取,后发现有相同类名爬取到多余内容,改用find()整不会了
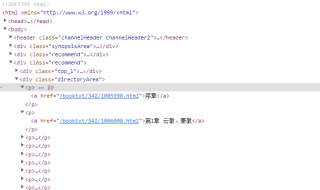
报错如图
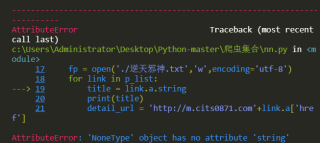
顺带问问章节a标签的href有分页怎么遍历
/booktxt/342/1005998.html
例如/booktxt/342/1005998_%d.html
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'
}
url = 'http://m.cits0871.com/booktxt/342/index_%d.html'
for pageNum in range(1,2):
# 对应页码的url
new_url = format(url%pageNum)
page_text = requests.get(url=new_url,headers=headers).text
soup = BeautifulSoup(page_text,'lxml')
p_list = soup.find('div',class_='recommend').find_next(class_='recommend').find_all('p')
#print(p_list)
fp = open('./Ntxs.txt','w',encoding='utf-8')
for link in p_list:
title = link.a.string
print(title)
detail_url = 'http://m.cits0871.com'+link.a['href']
detail_page_text = requests.get(url=detail_url,headers=headers).text
detail_soup = BeautifulSoup(detail_page_text,'lxml')
div_tag = detail_soup.find('div',class_='Readarea ReadAjax_content
content = div_tag.text
fp.write(title+':'+content+'\n')
print(title,'爬取成功')
我估计是link下边没有a,你取了没有的元素再调用string属性就报这个错了,你打印一下link看看吧
改成str(link.a)试试