请教一个pandas中groupby函数的问题
情况是这样的
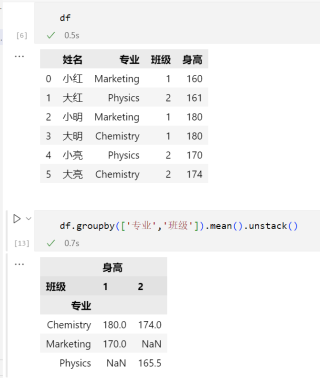
df = pd.DataFrame({'姓名':['小红' , '大红' , '小明' , '大明' , '小亮' , '大亮'],'专业':['Markrting' , 'Physics' , 'Marketing' , 'Chemistry' , 'Physics' , 'Chemistry'],'班级':[1,2,1,1,2,2],'身高':[160,161,180,180,170,174]})
请问要如何用groupby达到以下输出样式:
班级 1 2
专业
Chemistry 180 174
Marketing 170 0
Physics 0 165.5
(数值是身高均值)
# pd.options.display.precision = 0 # 取整的后果 165.5显示成166
df.groupby(['专业','班级']).mean().unstack().fillna(0) # fillna(0) 用0替代NaN
'''--result
身高
班级 1 2
专业
Chemistry 180 174
Marketing 170 0
Physics 0 166
'''
花了大半时间才发现你的marketing有一个拼错了。如果完全要按你的格式输出,应该用的是poivt_table
pd.pivot_table(df,index='专业',columns='班级',values='身高',fill_value=0).astype('int64')