python将编号相同的一列按固定值拆分
问题遇到的现象和发生背景
希望将v这一列按照buck这一列进行拆分,同一个buck的量应该为326881602,拆分结果应该为标黄的vol这一列,如果buck的值相同,比如都为1,可以看到D2位置应该填326881602,如果buck都为3,那么对应的v这一列的值的和为326881602,也即D4+D5=326881602。
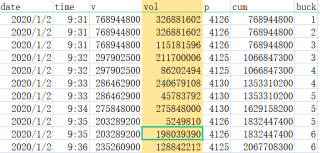
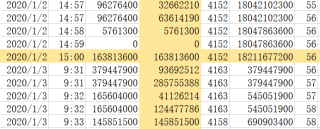
另外需要注意,对于新的一天,比如2020/1/3,9:31分的buck和2020/1/2的buck同为56,这就需要参考2020/1/2,14:57-15:00的v这一列,标黄的vol这一列是正确的结果,怎么才能得到
代码写长了一不小心,题主先试试行不行,数据格式没问题是前提,个别细节不懂可以留言
import pandas as pd
df = pd.read_csv('test.csv')
v_idx = list(df.columns).index('v')
df.insert(v_idx+1, column = 'vol', value = '')
b_idx = list(df.columns).index('buck')
df.loc[df['buck'].duplicated(keep = False) == False, 'vol'] = 326881602
df.loc[df['buck'].duplicated(keep = False) == True, 'vol'] = 0
v_set = list(set(df['v']))
b_set = list(set(df['buck']))
def v_checker():
flag = 0
for v in v_set:
part = df.loc[df.v == v]
check = 0
for row in range(part.shape[0]):
check += int(part.iloc[row, v_idx + 1])
if check != int(v):
flag += 1
else:
flag = flag
if flag == 0:
return True
else:
return False
def b_checker():
flag = 0
for b in b_set:
part = df.loc[df.buck == b]
check = 0
for row in range(part.shape[0]):
check += int(part.iloc[row, v_idx + 1])
if check != 326881602:
flag += 1
else:
flag = flag
if flag == 0:
return True
else:
return False
def v_correct():
global df
dfs = []
for v in v_set:
part = df.loc[df.v == v]
check = 0
for row in range(part.shape[0]):
check += int(part.iloc[row, v_idx+1])
if check != int(v):
if check > int(v):
over = check - int(v)
max_row = part.shape[0]-1
part.iloc[max_row, v_idx+1] -= over
dfs.append(part)
elif check < int(v):
loss = int(v) - check
min_row = part.shape[0]-1
part.iloc[min_row, v_idx+1] += loss
dfs.append(part)
else:
dfs.append(part)
df = dfs[0]
for index in range(1, len(dfs)):
add = dfs[index]
df = pd.concat([df, add])
df.sort_index(ascending=True, inplace = True)
def b_correct():
global df
dfs = []
for b in b_set:
part = df.loc[df.buck == b]
check = 0
for row in range(part.shape[0]):
check += int(part.iloc[row, v_idx+1])
if check != 326881602:
if check > 326881602:
over = check - 326881602
max_row = part.shape[0]-1
part.iloc[max_row, v_idx+1] -= over
dfs.append(part)
elif check < 326881602:
loss = 326881602 - check
min_row = part.shape[0]-1
part.iloc[min_row, v_idx+1] += loss
dfs.append(part)
else:
dfs.append(part)
df = dfs[0]
for index in range(1, len(dfs)):
add = dfs[index]
df = pd.concat([df, add])
df.sort_index(ascending=True, inplace = True)
def go():
try:
if v_checker() is False or b_checker() is False:
v_correct()
b_correct()
go()
else:
df.to_csv('res.csv', index = False) # 保存结果文件
except:
print('出问题了')
go()
print(df)
"""
实现的效果如下:
原数据
date time v buck
0 1 11 768944800 1
1 1 22 768944800 2
2 1 22 768944800 3
3 1 33 297902500 3
4 1 33 297902500 4
5 1 33 286462900 4
6 1 33 286462900 5
7 1 33 275848000 5
8 1 33 203289200 5
9 1 33 203289200 6
10 1 33 128842212 6
结果数据
date time v vol buck
0 1 11 768944800 326881602 1
1 1 22 768944800 326881602 2
2 1 22 768944800 115181596 3
3 1 33 297902500 211700006 3
4 1 33 297902500 86202494 4
5 1 33 286462900 240679108 4
6 1 33 286462900 45783792 5
7 1 33 275848000 275848000 5
8 1 33 203289200 5249810 5
9 1 33 203289200 198039390 6
10 1 33 128842212 128842212 6
"""
"""
答主好优秀的!我尝试运行了,一共有20000行数据,是数据太大了还是if语句嵌套的问题导致我运行一两个小时还不出结果?