根据条件向dataframe中增加行
问题遇到的现象和发生背景
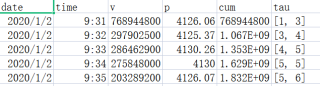
这里,对tau这一列,如果tau里面,右边的-左边的=1则增加一行,并且增加的一行为重复本行的值。
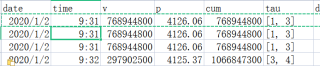
即对第一个数据[1,3],3-1=2,所以重复两行数据。变成下图
问题相关代码,请勿粘贴截图
import numpy as np
import pandas as pd
import csv
from scipy.stats import norm
from pandas import DataFrame
tau = pd.read_csv("C:/Users/DELL/Desktop/dthu.csv", header=0, usecols=['tau'])
tau = np.array(tau)
buck=[]
for x,y in range(len(tau)):
if y-x==0:
continue
if y-x!=0:
运行结果及报错内容
我的解答思路和尝试过的方法
我想要达到的结果
import pandas as pd
import numpy as np
def copy(df, row, exist): # 自定义函数,用以根据计算结果进行行的复制任务
idx = []
for r in range(exist):
idx.append(row)
return df.iloc[idx, :]
DF = pd.read_csv("test.csv", header=0)
tau = np.array(DF[['tau']])
"""
源文件的内容是这样的
date time tau
0 1 11 [1, 3]
1 2 22 [3, 4]
2 3 33 [5, 5]
"""
dfs = []
for t in range(len(tau)): # 遍历每一行,计算应产生几个表,然后将各部分存在dfs列表里
left = eval(tau[t][0])[0]
right = eval(tau[t][0])[1]
compare = right - left
EXIST = compare + 1
dfs.append(copy(DF, t, EXIST))
result = dfs[0]
for index in range(1, len(dfs)): # 拼接每个在dfs中的子结构
step = dfs[index]
result = pd.concat([result, step])
result.reset_index(drop = True, inplace = True) # 结果是拼凑而成的,所以可以重置以消除重复的索引
print(result) # to_csv()也可以写
"""
运行后的结果是这样的
date time tau
0 1 11 [1, 3]
1 1 11 [1, 3]
2 1 11 [1, 3]
3 2 22 [3, 4]
4 2 22 [3, 4]
5 3 33 [5, 5]
"""