利用python提取csv文件中特定列的字符(电话号码)
问题遇到的现象和发生背景
一个python初学者,想用正则表达式对应提取一个csv文件中指定列中的电话号码,并把提取的信息返还成列一一对应
问题相关代码,请勿粘贴截图
df = pd.read_csv("示例数据1.csv", encoding = 'gbk',header=0,sep=',')
file_cont = ''
def appaly_results(text):
text = df['text']
pattern = r"1[3-9]\d{9}"
results = re.findall(pattern,file_cont)
return results
df['phone'] = df['text'].apply(appaly_results)
df
运行结果及报错内容
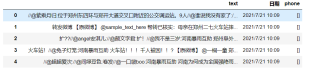
我的解答思路和尝试过的方法
我提取的结果phone列只有空的[],请求有人能给予指点
我想要达到的结果
为什么不能直接这样呢:df['phone'] = df['text'].apply(lambda x:re.findall(r"1[3-9]\d{9}",x))
你好,我其实不太明白这个file_cont = ''的作用是什么🤣
在这一行代码中,该函数传递参数为text,但是却没有使用,我初步猜测您是希望在这个地方使用,如果在该出使用那么程序将是正确的
您的写法
results = re.findall(pattern, file_cont)
我判断的写法
results = re.findall(pattern, text)
欢迎采纳!
最好给一点示例文本数据,不然这边不好考虑各种情况
参考上一位答主的代码,这样写就可以实现了
import pandas as pd
df = pd.read_csv("pd.csv", encoding='utf-8', header=0, sep=',')
df['phone'] = df['text'].apply(lambda x: re.findall(r"1[3-9]\d{9}", x)[0])
print(df)