CMD控制台设置UTF-8编码后,输入的中文只占一个字节?
问题遇到的现象和发生背景
通过chcp 65001将cmd控制台编码设成UTF-8。
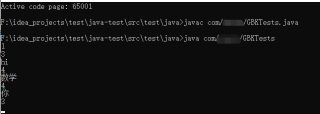
由图可知:
输入1,占3个字节,1占一个字节,回车符占2个字节,这是说得通的
输入hi也说得通
但是输入数学,占4个字节,输入你,占3个字节,就说不通了
输入数学,占4个字节,去掉回车符,还剩2个字节,那就是数学两个字各占一个字节,这说不通啊,有谁能帮忙解释一下么?(会不会是Java的System.in做了什么手脚?)
问题相关代码,请勿粘贴截图
下面是我的程序,从系统输入流中读取数据。
byte[] b = new byte[1024];
int len = -1;
while ((len = System.in.read(b))!= -1){
System.out.println(len);
}
运行结果及报错内容
我的解答思路和尝试过的方法
在Idea控制台输入,就很正常,一个中文占3个字节。可是CMD控制台设置chcp 65001之后怎么这么奇怪呢?
我想要达到的结果
utf-8默认中文就是3个字节的,还有些繁体是4/5个字节的,别怀疑,就是对的