如何获取元素在网页与背景图的对应关系
我想爬取一个网页,这个网页是个pdf文件,文件里的文字我都能通过数据包获取,但是涉及到图片的时候就不行了。它的图片都放在一张大背景图里,并且顺序很乱。
我想知道有没有什么办法能够获取图片在网页上以及在背景图的对应关系?
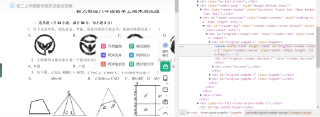


比较麻烦,实际他是通过css定位显示大图片中的指定位置的一小部分内容,而css还不知道他在那个文件中
好像没啥办法,你这相当于一个没有任何规律的图像分割识别,要实现貌似难度太大
我想爬取一个网页,这个网页是个pdf文件,文件里的文字我都能通过数据包获取,但是涉及到图片的时候就不行了。它的图片都放在一张大背景图里,并且顺序很乱。
我想知道有没有什么办法能够获取图片在网页上以及在背景图的对应关系?
比较麻烦,实际他是通过css定位显示大图片中的指定位置的一小部分内容,而css还不知道他在那个文件中
好像没啥办法,你这相当于一个没有任何规律的图像分割识别,要实现貌似难度太大