当爬取网页没有局部数据导致超出索引
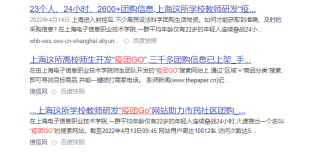
日期数据因为有两行是空的,就直接把最后一行的数据加进去了,怎么让空的地方变成空值或者字符串
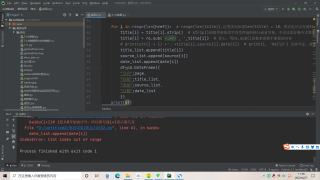
可以试着捕获IndexError,在date_list.append(date[i]),抛出异常date_list.append(None)
import requests
import re
import time
import random
from lxml import etree
import pandas as pd
iplist = []
with open("ip代理.txt") as f:
iplist=f.readlines()
#获取ip代理
def getip():
proxy= iplist[random.randint(0,len(iplist)-1)]
proxy = proxy.replace("\n","")
proxies={
'http':'http://'+str(proxy),
#'https':'https://'+str(proxy),
}
return proxies
def baidu(page):
num = (page-1)*10 # 参数规律是(页数-1)*10
url = 'https://www.baidu.com/s?wd=%E2%80%9C%E7%96%AB%E5%9B%A2GO%E2%80%9D&pn='+str(num)+'&oq=%E2%80%9C%E7%96%AB%E5%9B%A2GO%E2%80%9D&ie=utf-8'
requests.packages.urllib3.disable_warnings()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Accept-Encoding": "gzip, deflate, br",
"Host": "www.baidu.com",
"Cookie": "BAIDUID_BFESS=995C8ED53611A92AAA12C13A5FC5676C:FG=1; BAIDUID=63ACD89D1B351A56A0C29A8C5C2F932B:FG=1; BIDUPSID=63ACD89D1B351A56A0C29A8C5C2F932B; PSTM=1650682988; BD_UPN=19314753; BA_HECTOR=ak210084a12k808kp71h66r4c0r; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; baikeVisitId=1c4aa94e-b328-492c-89ce-a75bff6971be; channel=baidusearch; ab_sr=1.0.1_NTY3ZGZjMWE2M2E5NzdlYzI5MDFmNzAwZDY0OTIwZGE3ODVmODM4NjM2MzRkYTVhNmY5MGM2OWIwZjM2ZDY4OGRiNjQyM2NiMzVkZTQ4M2Q3ZWJkMzdlYmU0MDgzNTUwNDMxYjM5YTFjN2VmYmYwYjcyZTg3OWZmY2ExN2I4OGQwMTIwZjA0ZDdhNzQyODAyYzIxM2E2Y2NiNWMyMTY0OA==; delPer=0; BD_CK_SAM=1; PSINO=5; H_PS_PSSID=36309_31254_36019_36167_34584_36120_36125_35863_26350_36301_36312_36061; H_PS_645EC=a1735yAPfjtY4xVwy6SRH0y2onJRIapxQSAB4QZ%2F%2FA8bdPTLPQHjq2fWHbw"
}
response = requests.get(url=url,headers=headers,proxies=getip(),verify=False)
page_text = response.text
tree = etree.HTML(page_text)
href= tree.xpath('//*[@id]/div/div[1]/h3/a/@href')
print(href)
# 获取信息的标题
p_title = '<h3 class="c-title t t tts-title">.*?>(.*?)</a>'
title = re.findall(p_title,page_text,re.S)
print(title)
p_source = '<span class="c-color-gray" aria-hidden=.*?>(.*?)</span>'
source = re.findall(p_source, page_text)
print(source)
# 获取信息的日期
p_date = '<span class="c-color-gray2">(.*?)</span>'
date = re.findall(p_date,page_text)
print(date)
title_list=[]
source_list = []
date_list= []
for i in range(len(href)): # range(len(title)),这里因为知道len(title) = 10,所以也可以写成for i in range(10)
title[i] = title[i].strip() # strip()函数用来取消字符串两端的换行或者空格,不过这里好像不太需要了
title[i] = re.sub('<.*?>','',title[i]) # 核心,用re.sub()函数来替换不重要的内容
# print(str(i + 1) +'.'+title[i],source[i],date[i]) # print(1, 'hello') 这种写法,就是在同一行连续打印多个内容
title_list.append(title[i])
source_list.append(source[i])
date_list.append(date[i])
df=pd.DataFrame({
"页码":page,
"标题":title_list,
"来源":source_list,
"日期":date_list
})
print(df)
df.to_excel('./list.xlsx')
for i in range(8): # 这里一共爬取8页
baidu(i+1)# i是从0开始的序号,所以要写成i+1表示第几页
print('第'+str(i+1) + '页爬取成功') # i是从0开始的序号,所以写i+1
time.sleep(3)
日期数据是在哪里定义的,如果你知道最后两行是空的,那就不要遍历到最后两行啊,都没有肯定不能访问的,你根据i的值最后两个直接赋值不就行了,或者把date补齐