请问在scrapy shell调试中使用css完全无法提取数据是什么问题?
1.问题描述:今天爬取凤凰财经http://finance.ifeng.com/shanklist/1-64-/
,使用scrapy shell调试的时候,无论我用什么样的css语法都没法提取到数据,百度不到这样的问题,只好来求助了
(是初学者,目前只会css; xpath和正则在学习中)
2.代码部分
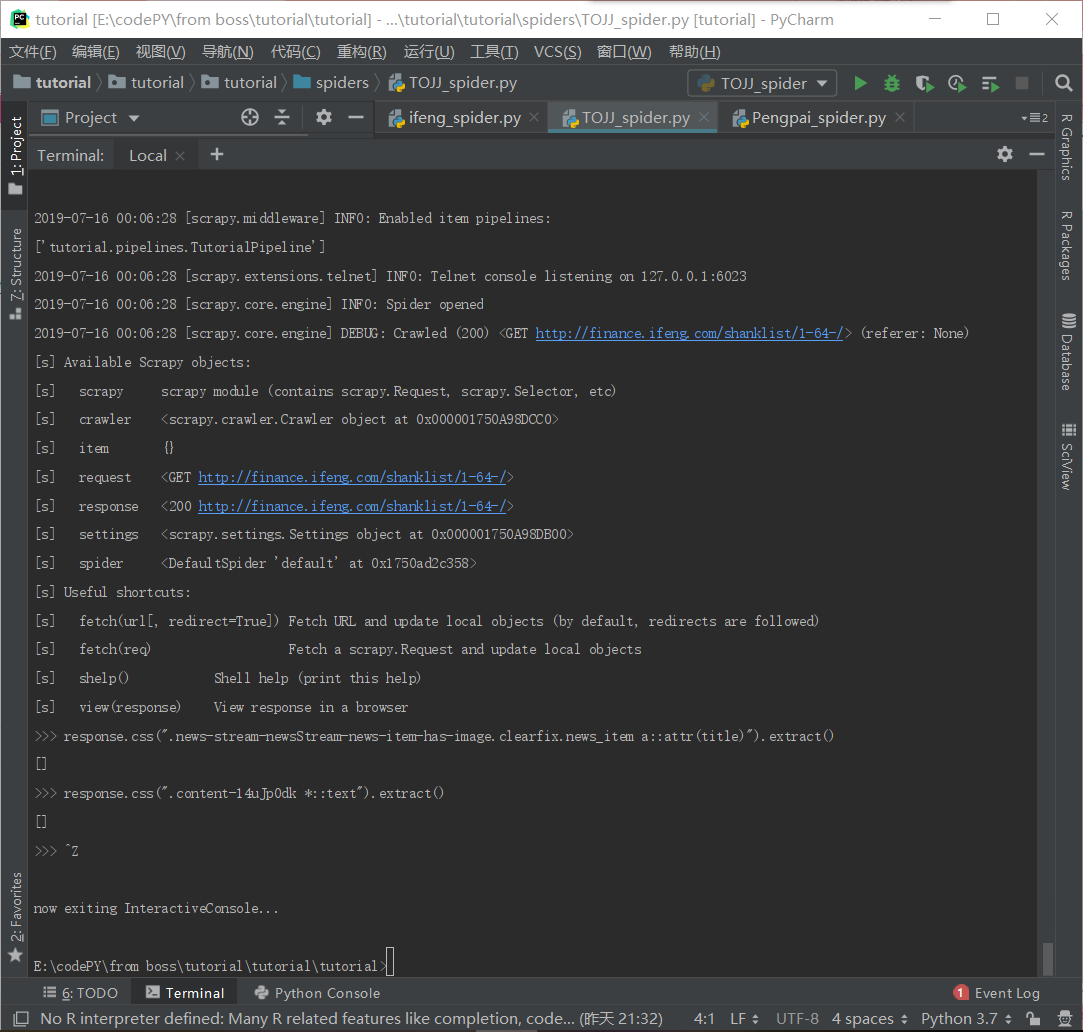
首先确认下获取到的响应文件中有没有数据,有些网站数据是动态加载的有可能你肯定就没有获取到数据 肯定就提取不到
如果确定有数据,在检查一下css语法有没有错误,
xpath很简单,正则最好用
我后来用response.text或者response.css("*::text").extract() 提取该页面的全部信息,发现标题url啥的都有,然后把提取到的全部信息转化成一个str,
然后再用正则表达式从中提取url和标题。
但是我回头检查我的语法确实没有错误,但也不能提取url和title
后来发现是这个网站很多数据都是都是动态加载,通过与服务器联系得到XHR包,但我想要的点赞收藏等数据我基本无力提取。
对于无法提取url和title,我猜测是网站结构也是动态生成,因为response.text并没有返回给我我那几句css语句对应的类和标签。