python sub()为什么把括号外的字符也替换了?
import re
a = "你在北京天安门:"
key1='北京'
rul5=re.compile(key1+r'+([\u4e00-\u9fa5]+):')
res5=rul5.findall(a)
res51=rul5.sub('中山路',a)
print(res5)
print(res51)
结果:
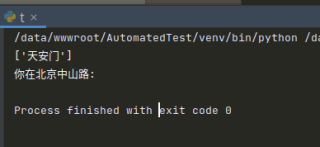
['天安门']
你在中山路
这是根据我代码简化的一个例子,findall是找出‘北京’后面的汉字‘天安门’,为什么sub会把‘北京’也替换了?需要怎么改?
import re
a = "你在北京天安门:"
key1='北京'
rul5=re.compile(key1+r'+([\u4e00-\u9fa5]+):')
res5=rul5.findall(a)
rul6 = re.compile(res5[0].encode('unicode_escape').decode('utf-8'))
res51=rul6.sub('中山路',a)
print(res5)
print(res51)
不知道这是不是你想要的
rul5 匹配的是 '北京天安门' 所以你用rul5.sub会把'北京'一起替换掉 用res5查出来的字符串重新生成一个正则就行了
findall()返回的是括号所匹配到的结果,多个括号就会返回多个括号分别匹配到的结果,
如果没有括号就返回就返回整条语句所匹配到的结果。
sub是整个匹配的串替换掉,要留分组内容,替换内容加上分组,如下

import re
a = "你在北京天安门:"
key1='北京'
rul5=re.compile(key1+r'+([\u4e00-\u9fa5]+):')
res5=rul5.findall(a)
res51=rul5.sub(r'中山路\g<1>',a)#######
print(res5)
print(res51)
替换内容详解repl是字符串
如果repl是字符串的话,其中的任何反斜杠转义字符,都会被处理的。
即:
\n:会被处理为对应的换行符;
\r:会被处理为回车符;
其他不能识别的转移字符,则只是被识别为普通的字符:
比如\j,会被处理为j这个字母本身;
反斜杠加g以及中括号内一个名字,即:\g,对应着命了名的组,named group
————————————————
版权声明:本文为CSDN博主「leo的学习之旅」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_43088815/article/details/90214217
