python 将csv转化为列表对象
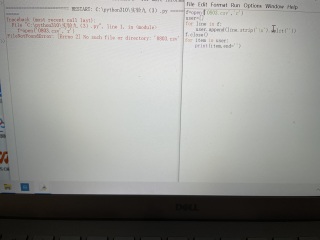
各位能帮助在下看一下发生了什么错误吗,明明是照着书上打的,就是报错。
import os
import pandas as pd
import numpy as np
from itertools import chain
# os.getcwd()读取当前路径
path = os.getcwd()+'\\eclipse-nnpom.csv'
df = pd.DataFrame(pd.read_csv(path,header=0))
df = pd.DataFrame(pd.read_csv(path,header=0,usecols=[0])) # header=0,表示第一行为标题行 usecols=[0]读取第一列
# reshape(行,列)可以根据指定的数值将数据转换为特定的行数和列数
# reshape(-1, 1) -1 数据集自适应行 1 数据集变成了一列
df =df.values.reshape(-1, 1)
dfa = np.array(df, dtype=float) # 将数据转为float型
dfb = dfa.tolist() # 转换为list型
# chain 接收多个可迭代对象作为参数,将它们连接起来,作为一个新的迭代器返回。
# 通俗来说,from_iterable可将dfb中的所有数据一个个输出
dfa1 = list(chain.from_iterable(dfb))
dfa1[::3] #间隔3个数据读取一个数据
這个報錯是文件未找到, 你看下源碼.py的文件位置和文件.csv文件的位置, 應該是0803.csv這个文件不在源碼路徑導致的
把.csv這个文件移動到C:\python310\這个文件夾去, 或者使用絕對路徑, 不要只寫文件名, 比如文件在桌面的話, 就寫
open('C:\Users\XXX\Desktop\0803.csv', 'r', encoding='utf-8'), xxx是你的電腦特有的路徑