python 文件读写操作 怎么写才能尽量少用循环语句同时完成 读取 筛选 写入 并输出?
假设我有一段数据,我怎么写才能尽量少用循环语句同时完成 读取 筛选 写入 并输出?
(循环用得越少越好)
data_txt = """
id date city temp wind
0 03/01/2016 BJ 8 5
1 17/01/2016 BJ 12 2
2 31/01/2016 BJ 19 2
3 14/02/2016 BJ -3 3
4 28/02/2016 BJ 19 2
5 13/03/2016 BJ 5 3
6 27/03/2016 SH -4 4
7 10/04/2016 SH 19 3
8 24/04/2016 SH 20 3
9 08/05/2016 SH 17 3
10 22/05/2016 SH 4 2
11 05/06/2016 SH -10 4
12 19/06/2016 SH 0 5
13 03/07/2016 SH -9 5
14 17/07/2016 GZ 10 2
15 31/07/2016 GZ -1 5
16 14/08/2016 GZ 1 5
17 28/08/2016 GZ 25 4
18 11/09/2016 SZ 20 1
19 25/09/2016 SZ -10 4
"""
#这个是存储的电脑上的data.txt 文件
import re
with open('data.txt','r') as f:
for line in f.readlines()[1:]:
if len(line.split()) == 0:
continue
j = re.split(r"\s+",line.rstrip())
k = int(j[1].split("/")[1])
if k >= 1 and k <= 12 and j[2] == 'SH': #找出几月份的XX城市的数据
print(j)
a = []
b = []
with open('data.txt','r') as f:
for line in f.readlines()[1:]: #找出XX城市的温度和风力等级并算出平均值
if len(line.split()) == 0:
continue
j = re.split(f'\s+',line.rstrip())
if(j[2] == 'SH'):
a.append(int(j[3]))
b.append(int(j[4]))
print("\nHS temp平均值为{} wind平均值为{}".format(sum(a)/len(a),sum(b)/len(b)))
运行结果及报错内容
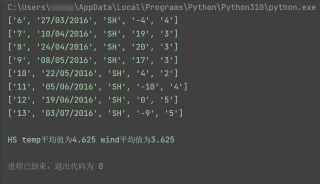
问题
- 筛选XX城市的天气数据比如SH 1月到12月的数据
- 计算出该城市的 1-12月的 温度和风力的平均值
- 把筛选和计算出来的数据存储到另外一个txt文件
(还能有更简单的写法吗?代码越简单越好)
'''
考虑几个问题,你的数据是否是每年一个txt文件,并且严格按照日期形式组织,如果是
根据需求,完全不需要判断月份,直接判断年份或者写个函数把年份作为参数。
'''
import time
#用闭包保存状态,统计结果,
def filter_total(year='2016',city="SH"):
res = {
'year': year ,
"city":city ,
"totemp":0,
"towind":0,
"num":0,
}
def total(line,):
nonlocal res
date,c,temp,wind = line
if year in date and city == c:
res["totemp"] += float(temp)
res["towind"] += float(wind)
res['num'] +=1
return res
return total
start = time.time()
num = 0
resdict2 = filter_total()
with open(r'd:\Users\Desktop\out.txt', "wt") as w :
with open(r"d:\Users\Desktop\aaa.txt",'rt') as r:
for i in r:
num += 1#计算性能需要,可以去掉
i = i.strip()#去除每行字符串两端空白
if not i or i.startswith("id"):#判断是否为空,或者首行
continue
else:
SH=resdict2(i.split()[1:])
rstr = "城市{},平均温度{},平均风速{}".format(SH["city"],
SH['totemp']/SH['num'],
SH['towind']/SH["num"],)
print(rstr)
w.write(rstr+'\n')
print("数据数量{}程序耗时{}".format(num,time.time()-start))
======================= RESTART: D:\Users\Desktop\test.py ======================
城市SH,平均温度4.625,平均风速3.625
数据数量645462程序耗时0.5146725177764893
>>>
pandas
用pandas包,可以快速过滤或聚合数据,
如果熟悉sql语法的话,再配上PandaSQL包,就可以写sql语句来查pandas的数据了。