如何修改EXCEL某列中部分单元格格式出现bug的数值
问题遇到的现象和发生背景
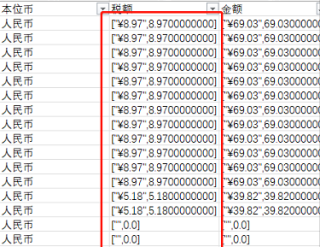
如上图,怎么用python 的pandas 把这些数值按正确的格式修正,我有几百个这样的表,每个表里部分列的部分单元格内容都出现了这种错误,我想导入pandas里批量修正。
操作环境、软件版本等信息
尝试过的解决方法
我想要达到的结果
import pandas as pd
import os
file_list=os.listdir()
try:
os.makedirs('./out')
except:
pass
for file in file_list:
if os.path.splitext(file)[1].lower()=='.xlsx':
try:
df = pd.read_excel(file)
df['税额']=df['税额'].str.extract(r'"¥(.*)"')
df.to_excel(f'./out/{os.path.splitext(file)[0]}_changed.xlsx', index=None)
except:
pass
所有excel放在同一个文件夹就能用,自动转化在out文件夹内并重新命名。
你需要遍历每一个表,然后修改
data["税额"] = [round(i[1],2) for i in data["税额"].values ]
data["金额"] =[round(i[1],2) for i in data["金额"].values ]
再写入原表
如果数据的位置都是一样的话,就可以用以下方法,若是不一样的话可以参考上面回答中使用正则表达式的那种办法
文件导入:df = pd.read_excel()
df['税额'] = float(str(df['税额'])[3:7])
import os
import pandas as pd
# 新建名为original的文件夹,把要修改的excel都放进去
SheetsList=os.listdir("./original")
col=["税额","金额"] # 要修改的列都放进去
try:
os.makedirs('./output')
except:
pass
for Sheets in SheetsList:
sheet=pd.read_excel("./original/"+Sheets)
for key in col:
sheet[key]=sheet[key].apply(lambda x: x.split('"')[1])
sheet.to_excel("./output/"+Sheets,index=None)