Hive的MR引擎或者Tez引擎中reduce的数量到底是由什么决定的?
理论上来说,不是说一种key对应一个reduce吗,但是为什么我这样跑一个任务,对应的key应该是data_dt吧,但是data_dt也没有1000多个呀,为什么有1000多个reduce呢?
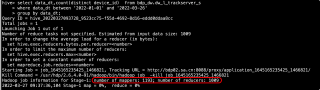
可以设置reduce的参数的
set mapreduce.reduce.tasks
可以直接设置有多少个task
如果没有指定reduce个数,
通过hive.exec.reduces.bytes.per.reducer参数来设定每个reducer处理的bytes。
这个参数越大,reducer就越少。
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632