Python异步(asyncio)请求--同步的问题错误
问题遇到的现象和发生背景
使用asyncio、aiohttp提取一些链接时,过程中解析那里出现问题
问题相关代码,请勿粘贴截图
from pyquery import PyQuery
import os
import asyncio
import aiohttp
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
# 并发量设置
semaphore = asyncio.Semaphore(5)
# 获取一个请求里的所有img页面详情链接
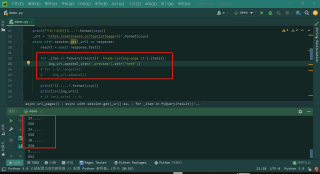
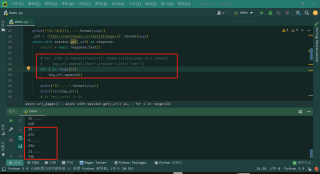
async def url_pages(page):
# async with semaphore:
print("开始下载第{}页...".format(page))
_url = 'https://wallhaven.cc/toplist?page={}'.format(page)
async with session.get(_url) as response:
async with lock:
result = await response.text()
for _item in PyQuery(result)('.thumb-listing-page li').items():
img_url.append(_item('.preview').attr('href'))
# for i in range(24):
# img_url.append(i)
print("{}.....".format(page))
print(len(img_url))
# 主方法
async def scrape_main():
global session
session = aiohttp.ClientSession()
scrape_index_tasks = [asyncio.ensure_future(url_pages(page)) for page in range(1, pages+1)]
await asyncio.wait(scrape_index_tasks)
await session.close()
if __name__ == '__main__':
pages = 30
img_url = []
session = None
lock = asyncio.Lock()
asyncio.get_event_loop().run_until_complete(scrape_main())
运行结果及报错内容
就是为什么中间那部分解析的内容没有添加都列表,而用普通的for循环却可以。
表示很懵!
正常应该是720的,结果就只添加了528.
我的解答思路和尝试过的方法
并发量控制尝试过,Lock也尝试过,还是解决不了
我想要达到的结果
30页的内容,没页解析出24条数据,一共720条数据才对,现在的问题就是,中间有些内容解析的数据没有添加成功,请解惑o(╥﹏╥)o
你定义了个lock变量,然后在哪用了,哪里也没用啊
你需要这样
with lock:
#do something
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632