求用c语言回答,实在不会做了
问题描述:文学研究人员需要编辑文章、统计某篇英文小说中某些词的出现次数和位置。设计一个实现这一目标的文字统计系统。
要求:英文小说存于一个文本文件中。
(1)分别统计出其中英文字母数和空格数及整篇文章总词数;
(2)统计某一字符串在文章中出现的次数和出现的位置(输出行号,或高亮显示);
(3)删除某一子串,并将后面的字符前移。
输出形式:
(1)分行输出用户输入的各行字符;
(2)分4行输出“全部字母数”、“数字个数”、“空格个数”、“文章总字数”;
(3)删除某一字符串后的文章写入文件中。
- 这篇博客: 《C语言程序设计》实训报告中的 1.由键盘上输入一行以回车结束的字符,分别统计出其中英文字母、空格、数字和其他字符的个数 部分也许能够解决你的问题, 相关内容:
文字:
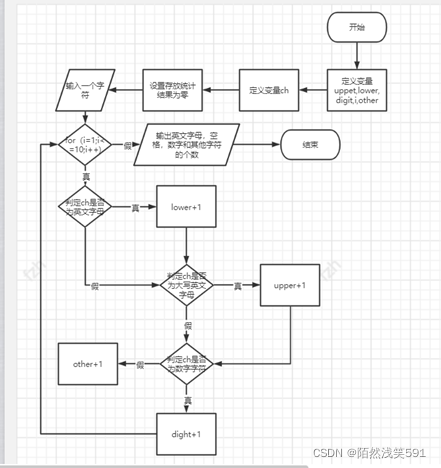
- 定义变量upper,lower,digit,i,other;
- 定义变量ch;
- 设置存放统计结果为零;
- 输入十个字符;
- 判定是否执行了十次,是则转第⑩步,否则转第⑥步;
- 判定ch是否为小写英文字母,是则lower+1,否则转第⑦步;
- 判定ch是否为大写英文字母,是则upper+1,否则转第⑧步;
- 判定ch是否为数字字符,是则digit+1,否则other+1;
- 转第⑤步;
- 输出英文字母、空格、数字和其他字符的个数;
流程图:
代码:
#include<stdio.h>
int main()
{
int upper, lower, digit, i, other;
char ch;
upper = lower = digit = other = 0;
printf("输入10个字符 :");
for (i = 1; i <= 10; i++)
{
ch = getchar();
if (ch >= 'a' && ch <= 'z')
lower++;
else if (ch >= 'A' && ch <= 'Z')
upper++;
else if (ch >= '0' && ch <= '9')
digit++;
else
other++;
}
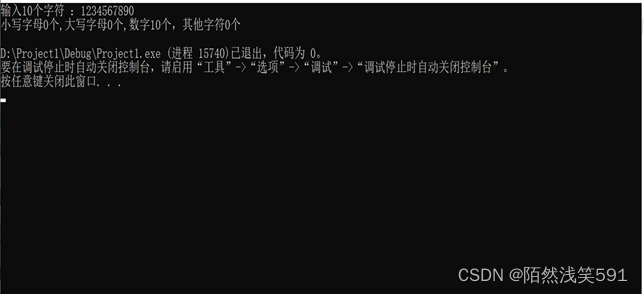
printf("小写字母%d个,大写字母%d个,数字%d个,其他字符%d个\n", lower, upper, digit, other);
return 0;
}
执行结果:
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^