网络爬虫爬百度时乱码问题
网络爬虫使用requests爬取百度出现了乱码l,搜狗确实正常的,请问怎么解决?
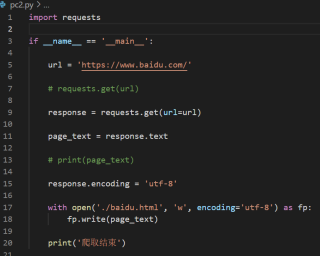
response.encoding=utf-8放上来
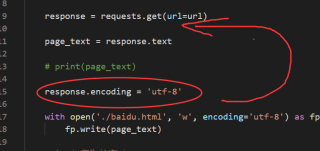
import requests
url='https://www.baidu.com/'
r=requests.get(url)
r.encoding='utf-8'
print(r.text)

#导入requests库
import requests
#目标网站的网址
url='https://www.baidu.com/'
#调用request里的get方法发送请求
response=requests.get(url)
response.encoding='utf-8' #结果中汉字是乱码,这里编码一下
#返回的response是一个response对象,我们需要text文本
resp=response.text
##打印结果
#print(resp)
#保存文件
withopen("./baidu.html","w",encoding='utf-8') as fp:
fp.write(resp)
print("文件保存完成!")

我之前写的,有帮助的话采纳一下哦!您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632