关于#python#的问题:在"ABC" < "上海"比较中, 为什么会是ture值
在字符串的比较中
字母“ABC”和中文字符”上海“比较,为什么会是true值
求指教,谢谢
我刚刚测试了一下,他俩比较大小的时候才会出现True
原因如下:
计算机存储的都是二进制,那么我们将他们都转为二进制来算
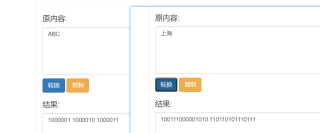
位数不够的在左边补0。
因此 ABC < 上海 的结果为True
我认为这个有依据,因为在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。然后做比较的话,应该会统一转为二进制进行比对,结果就是如上图。参考的资料如下
用ord()来逐个比较字符大小。ascii字母 0~127,汉字是Unicode string,数值肯定大
chr(i, /)
Return a Unicode string of one character with ordinal i; 0 <= i <= 0x10ffff.
例:
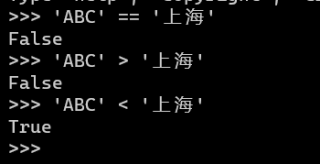
>>> "ABC" < "上海"
True
>>> "ABC" < "ABB上海"
False
>>> "AB上" < "AB海"
True
>>> ord('上')
19978
>>> ord('海')
28023
看看这个,就明白了。
print("ABC".encode('utf8')[0])
print("上海".encode('utf8')[0])
字符串按位比较,两个字符串第一位字符的ascii码谁大,字符串就大,不再比较后面的;第一个字符相同的情况下,就比第二个字符串,以此类推版。
两个字符串进行比较,这是语法基础,你应该掌握
当两个字符串进行比较时,按照从0开始的索引依次比较每个字符,直到字符大的那一个为止,作为整个字符串的比较结果
如果两个字符串前面的字符完全相同,而一个长一个短,那么长的值大,因为短的结束符是0,是所有字符里最小的