java代码写千万级数据同步
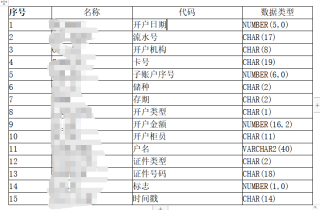
这样的一张表,有一千五百万的数据量,需要搬到另一个数据库里,应该怎么处理比较快,datax同步这张表时报违法协议,没得办法只能自己写同步的代码了,应该卡号是主键或索引
可以考虑分成多线程进行处理,比如
线程1处理序号1、4、7……
线程2处理序号2、5、8……
线程3处理序号3、6、9……
是一次性操作还是经常要使用的操作?
如果是一次性的,为何不直接用数据库自带的工具导出再导入呢?这样省去各种不必要的中间环节,一次性就搬完了。
如果是要经常使用的操作,每次都全量同步的话,需求是不是不太合理?
是oracle的dblink?网络带宽及稳定性怎么样?
如果网络带宽及稳定性好的话,且两边都是oracle,你这才千万级数据,直接一个ctas就完了,这样的性能瓶颈在网络带宽上
create table xxxx as select * from yyyyy@dblink
如果担心一次性吃不下,就按开户日期范围,分批create成多张表,最后再合并
xtrabackup备份还原一下,然后增量同步过去。
datax是可以的,json估计没配置对吧
也可以用kettle试试