python-docx 库自动根据 工序数量 依次在word表格内填充内容
本代码使用编辑器:Python
所需库: Python-docx
现在有一个20行、4列的表格,其中第1行 至 第9行均有固定数据填充,因此需求根据一个品种的工序步骤次数来判断填充内容(从第10行开始)。
工序 = “整理、粉碎、清洗、切制、干燥”
b =工序.split('、') #以顿号来分割
b = ['整理', '粉碎', '清洗', '切制', '干燥']
h = len (b) #判断为5个工序
z = 0
while z < h:
for n in range(0,h) #遍历行(最大值为工序数) ← 这里有点问题,是根据内容依次填充确定行数,而不是直接定好行数,这里应该需要修改。
for m in range(0,2): #遍历列(0、1列)
k = m*2 #奇偶列填充
if '整理' in b: #如果出现含有整理的字样,从第10行开始,第0列和第一列填充内容
document.tables[9].cell(10+n,k).text =' 内容balabalabala'
document.tables[9].cell(10+n,k+1).text =' 内容abababababab'
if '粉碎' in b:
document.tables[9].cell(10+n,k).text =' 内容balabalabala111111'
document.tables[9].cell(10+n,k+1).text =' 内容abababababab111111'
z = z + 1
现在属于是逻辑混乱的,希望热心网友能给个清晰的思路,上述代码跑出来的结果如下:
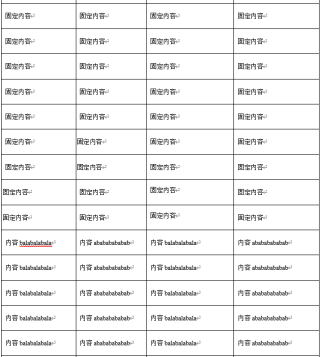
而我想要的结果是如下:
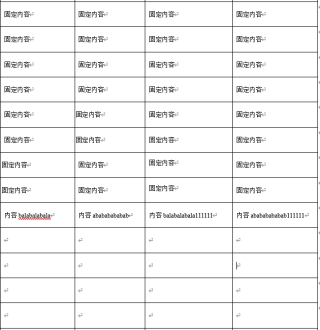
上述省略了其余两道工序对应的内容。
1.如果工序len 出来有5次,需要从第10行开始填充5次,每次为第0列和第1列,然后第2列,第3列,再第二行的第0列,第一列,以此类推。
我猜题主的意思是每个工序填充两列,下一个工序接着当前工序填充,我这里写了一个Demo,你看看是不是你的意思:
from docx import Document
document = Document('temp.docx')
工序 = "整理、粉碎、清洗、切制、干燥"
b =工序.split('、') #以顿号来分割
h = len (b) #判断为5个工序
fill_length = 36 # 填充的格数,已经填充了9行共36格
for n in range(0, h):
cur_process = b[n] # 获取工序
cur_row = fill_length // 4 + 1 # 获取待填充的行数,一行4格的话就除以4
if fill_length % 4 == 0: # 若当前填充格数除的尽,说明当前行填满,下一行填充0,1列
cur_col = 0
else: # 若除不尽,说明当前行还没填满,4格只填充了2格,继续填充当前行的2,3列
cur_col = 2
print(cur_process, cur_row, cur_col)
if cur_process == '整理':
# cur_row减1是因为cell是从0开始索引的,而计算的时候我们是从1开始的
document.tables[0].cell(cur_row - 1, cur_col).text = ' 内容balabalabala'
document.tables[0].cell(cur_row - 1, cur_col + 1).text = ' 内容balabalabala'
elif cur_process == '粉碎':
document.tables[0].cell(cur_row - 1, cur_col).text = ' 内容balabalabala111111'
document.tables[0].cell(cur_row - 1, cur_col + 1).text = ' 内容abababababab111111'
fill_length += 2
document.save("temp.docx")
我按照你的意思创建了一个temp.docx,其中前9行填充了固定内容,即:
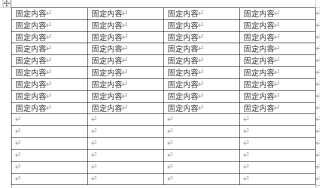
处理后是这样的:
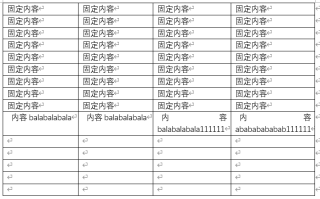
你说的我也没太听懂。是说第一个工序填充第10行前两列,第二个工序填充第10行后两列,然后填充5行,这5行是一样的吗?
import xlrd
import xlwt
python这两个模块可以读取excel表格,然后你定位指针到你表格的10行,开始写入你的数据。