Python爬虫 xpath 列表为空
用python爬取房天下的详情页,但是只有物业类别可以爬出来,其他均为空
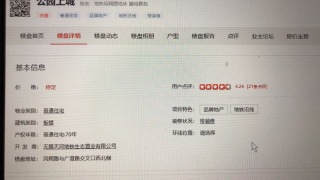
原网址:https://wuxi.newhouse.fang.com/house/s/b91/
第二个li的div下少了结束标签导致etree解析出错了
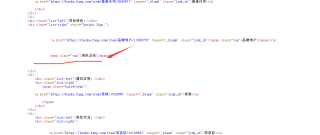
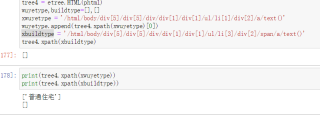
少了div结束标签后,etree将建筑类别后的几点全部归类到第二li下了,改下面这样就可以了
import requests
from lxml import etree
from lxml import html
url="https://wuxi.newhouse.fang.com/loupan/1821129836/housedetail.htm"
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'}
html=requests.get(url,headers=headers).text
tree=etree.HTML(html)
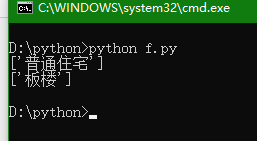
print(tree.xpath('/html/body/div[5]/div[5]/div/div[1]/div[1]/ul/li[1]/div[2]/a/text()'))
print(tree.xpath('/html/body/div[5]/div[5]/div/div[1]/div[1]/ul/li[2]/div[2]/li[1]/div[2]/span/a/text()'))
这种不规则的html代码建议用正则或者bs4来解析。

PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632