python+selenium+xpath如何定位网页table表格中的数据
如何获取网页表格中的猪肉价格?每个页面的猪肉价格所在行是变化的,如何精准定位到猪肉行?
我的代码该如何修改才能精准爬取猪肉价格呢?
from selenium.webdriver.common.by import By
from selenium import webdriver #导入selenium
url= input("请输入网址:")
driver = webdriver.Chrome() #打开浏览器
driver.maximize_window() # 将浏览器最大化
driver.get(url) #打开网址
猪肉价格 = driver.find_element(By.XPATH,'/html/body/table/tbody/tr[5]/td[2]').text # xpath定位猪肉价格
print("猪肉价格是:",猪肉价格) # 打印猪肉价格
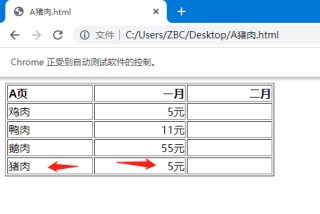
以下是页面A的源代码
<html>
<body>
<table width="400" border="1">
<tr>
<th align="left">A页</th>
<th align="right">一月</th>
<th align="right">二月</th>
</tr>
<tr>
<td align="left">鸡肉</td>
<td align="right">5元</td>
<td align="right"></td>
</tr>
<tr>
<td align="left">鸭肉</td>
<td align="right">11元</td>
<td align="right"></td>
</tr>
<tr>
<td align="left">鹅肉</td>
<td align="right">55元</td>
<td align="right"></td>
</tr>
<tr>
<td align="left">猪肉</td>
<td align="right">5元</td>
<td align="right"></td>
</tr>
</table>
</body>
</html>
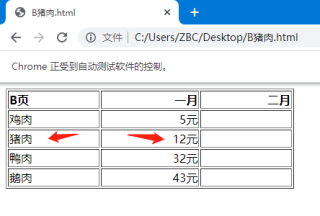
以下是页面B的源代码
<html>
<body>
<table width="400" border="1">
<tr>
<th align="left">B页</th>
<th align="right">一月</th>
<th align="right">二月</th>
</tr>
<tr>
<td align="left">鸡肉</td>
<td align="right">5元</td>
<td align="right"></td>
</tr>
<tr>
<td align="left">猪肉</td>
<td align="right">12元</td>
<td align="right"></td>
</tr>
<tr>
<td align="left">鸭肉</td>
<td align="right">32元</td>
<td align="right"></td>
</tr>
<tr>
<td align="left">鹅肉</td>
<td align="right">43元</td>
<td align="right"></td>
</tr>
</table>
</body>
</html>
使用last()定位最后 一个tr节点,再用索引获取。示例:
from lxml import etree
with open('a.html','r',encoding='utf-8') as f:
html=f.read()
driver=etree.fromstring(html)
猪肉价格 = driver.xpath('//tr[last()]/td[2]')[0].text # xpath定位猪肉价格
print("猪肉价格是:", 猪肉价格) # 打印猪肉价格
输出:
F:\2022\pythontest>t3
猪肉价格是: 5元
如有帮助,请点采纳。
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632