Python爬虫 错误:json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
一、问题
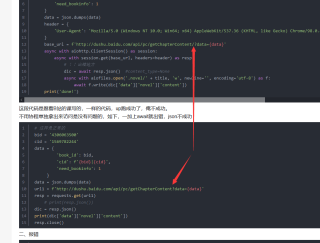
练习协程,使用aiohttp.ClientSession().get(url).json()报错,代码如下:
async def aiodownload(bid, cid, title):
# 异步任务
data = {
'book_id': bid,
'cid': f'{bid}|{cid}',
'need_bookinfo': 1
}
data = json.dumps(data)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
base_url = f'http://dushu.baidu.com/api/pc/getChapterContent/?data={data}'
async with aiohttp.ClientSession() as session:
async with session.get(base_url, headers=header) as resp:
# !!出错地方
dic = await resp.json() #content_type=None
async with aiofiles.open('.novel/' + title, 'w', newline='', encoding='utf-8') as f:
await f.write(dic['data']['novel']['content'])
print('done!')
这段代码是跟着B站的课写的,一样的代码,up跑成功了,俺不成功。
不用协程单独拿出来访问是没有问题的,如下,一加上await就出错,json不成功
# 这样是正常的
bid = '4306063500'
cid = '1569782244'
data = {
'book_id': bid,
'cid': f'{bid}|{cid}',
'need_bookinfo': 1
}
data = json.dumps(data)
url1 = f'http://dushu.baidu.com/api/pc/getChapterContent?data={data}'
resp = requests.get(url1)
# print(resp.json())
dic = resp.json()
print(dic['data']['novel']['content'])
resp.close()
二、报错
Task exception was never retrieved
in json raise ContentTypeError(
aiohttp.client_exceptions.ContentTypeError: 0, message='Attempt to decode JSON with unexpected mimetype: text/html; charset=utf-8',
Process finished with exit code 0
三、尝试解决(全是在网上搜的解决办法
json()里指定类型,dic = await resp.json(content_type=None, encoding='utf-8)
还是报错:json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0),这个错误没找到解决办法
刚开始学,不知如何下手解决,礼貌求解!
async+await方法的url多了个斜杠,去掉就行了。要不多的那个斜杠接口出错返回的是html代码了,调用json()出错了,内容不是json字符串
测试代码如下
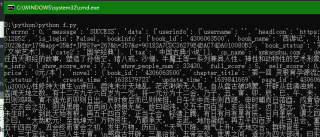
import json
import aiohttp
import asyncio
async def aiodownload(bid, cid, title):
# 异步任务
data = {
'book_id': bid,
'cid': f'{bid}|{cid}',
'need_bookinfo': 1
}
data = json.dumps(data)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
base_url = f'http://dushu.baidu.com/api/pc/getChapterContent?data={data}'
async with aiohttp.ClientSession() as session:
async with session.get(base_url, headers=header) as resp:
# !!出错地方
dic = await resp.json() #content_type=None
#async with aiofiles.open('.novel/' + title, 'w', newline='', encoding='utf-8') as f:
#await f.write(dic['data']['novel']['content'])
print(dic)
loop = asyncio.get_event_loop()
loop.run_until_complete(aiodownload('4306063500','1569782244','xxx'))

这种报错一般都是json数据出错,么有拿到json数据,可能协程出问题了吧,可以打印看一下要爬的json数据是否可以print出来
不错不错,支持支持
resp的到json 解码出错了。resp的可能不是合法的json数据,可以判断下。
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632