为什么爬取的网站,页面代码少了好多,然后网站显示空白
不知道为什么和网上up主输入的代码是一样的,但是最后爬取的网站页面代码和界面显示结果不一样。
你是用requests爬取网页的吗
你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的内容取不到。
对于动态更新的内容要用selenium 来爬取。
或者是通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。
在页面上点击右键,右键菜单中选 "查看网页源代码"。
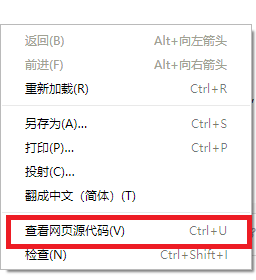
这样看到的才是网页的静态源代码。
如果这个网页的静态源代码中有你需要爬取的内容,就说明该页面没有动态内容,可以用requests爬取。
否则就说明该页面的内容是动态更新的,要用selenium 来爬取.
如果这个网页的静态源代码中有你需要爬取的内容,res.text中却没有,可能是requests伪造的头部信息不全。
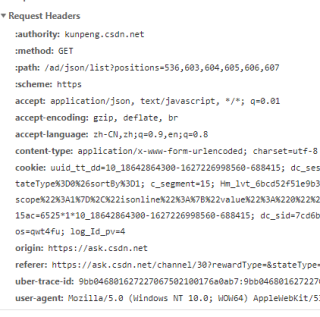
要在headers中添加抓包时的请求头求参数
headers={
'User-Agent': 'xxxxxxxxxxx',
'Host' : 'xxxxxxxxxxx',
'Origin' : 'xxxxxxxxxxxxx',
'Referer' : 'xxxxxxxxxxxxxx',
'Cookie': 'xxxxxxxxxxxxxxxx'
}
其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到
如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!

import requests
headers = {"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"}
response = requests.get("https://www.baidu.com", headers=headers)
with open("my.html","w",encoding="utf-8") as fp:
fp.write(response.content.decode())
print("over!")
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632