python爬虫使用json()方法将response结果转化为JSON格式时报错
问题遇到的现象和发生背景
python爬虫使用json()方法将response结果转化为JSON格式时报错simplejson.errors.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
问题相关代码,请勿粘贴截图
try:
response = requests.get(url)
if response.status_code == 200:
print('连接成功')
print(type(response))
return response.json()
else:
print(response.status_code)
运行结果及报错内容
import requests
from urllib.parse import urlencode
def get_page(page_num):
params = {
"keyword": "街拍",
"pd": "atlas",
"source": "search_subtab_switch",
"dvpf": "pc",
"aid": "4916",
"page_num": page_num,
"rawJSON": "1",
"search_id": "202202111136570101501341604D100200"
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response = requests.get(url)
if response.status_code == 200:
print('连接成功')
print(type(response))
return response.json()
else:
print(response.status_code)
except requests.ConnectionError:
print('连接失败')
return None
我的解答思路和尝试过的方法
1、原网页是不是json格式内容。 是
2、测试是否被反爬 没有被反爬
3、
我想要达到的结果
能将response转换为JSON格式
网站设计了相应的反扒策略,需要把Cookie添加到headers中,这种问题一般从headers入手,有的限制User-Agent必须有,有的限制Cookie
headers = {
'Cookie':'xxxxxxxxxxxxxxx'
}
response = requests.get(url, headers=headers)
Cookie获取方法:
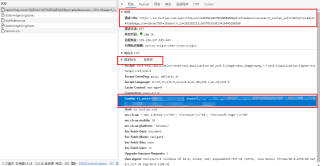
你这个地址得到源码不是json数据格式,网页数据是js动态生成的,浏览器打开是渲染后的json数据,爬虫得到的是这个

你看下response.text ,其实并没有拿到数据,所以转json 出错。 你请求里加上Cookie 就可以了
对的,以上几个回答都正确,加入cookie,就解决了。非常感谢