xpath爬取图片,得不到src ,python求解决
import requests
from lxml import etree
def main():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3883.400 QQBrowser/10.8.4559.400'}
url = "https://pic.sogou.com/pics?query=%E4%BA%94%E6%98%9F%E7%BA%A2%E6%97%97%E5%9B%BE%E7%89%87&rawQuery=%E4%BA%94%E6%98%9F%E7%BA%A2%E6%97%97%E5%9B%BE%E7%89%87&st=255&mood=5&dm=0&mode=1"
resp = requests.get(url, headers=headers)
resp.encoding = "utf-8"
child_tree = etree.HTML(resp.text)
imgs = child_tree.xpath('//div[@class="figure-result"]//a/img')
for img in imgs:
src = img.xpath('./@src')
print(src)
if __name__ == '__main__':
main()
图片是js解析出来的,xpath无效,数据在js变量里面,正则提取下数据用json.loads加载获取

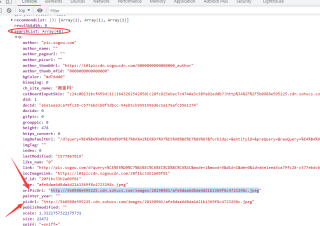
代码如下
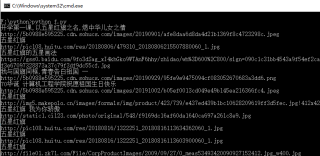
import requests
import re
import json
def main():
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3883.400 QQBrowser/10.8.4559.400'}
url = "https://pic.sogou.com/pics?query=%E4%BA%94%E6%98%9F%E7%BA%A2%E6%97%97%E5%9B%BE%E7%89%87&rawQuery=%E4%BA%94%E6%98%9F%E7%BA%A2%E6%97%97%E5%9B%BE%E7%89%87&st=255&mood=5&dm=0&mode=1"
resp = requests.get(url, headers=headers)
resp.encoding = "utf-8"
jsonstr=re.findall(r'window\.__INITIAL_STATE__=(.+?);\(function\(\){var s;',resp.text,re.S)[0]
data=json.loads(jsonstr)
for item in data['searchList']['searchList']:
print(item['title'])
print(item['picUrl'])
'''
child_tree = etree.HTML(resp.text)
#imgs = child_tree.xpath('//div[@class="figure-result"]//a/img')
#for img in imgs:
# src = img.xpath('./@src')
print(src)
'''
if __name__ == '__main__':
main()

可能是反爬了,你输出resp.text看看响应内容和你网页看到是不是一样
麻烦把imgs输出一下看看
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632