用python读取cvs指定几个位置的前后组数据到all.cvs 列排成行
用python读取999999.cvs指定几个位置的30组数据(前后15个)*到all.cvs 列排成行
如图所示
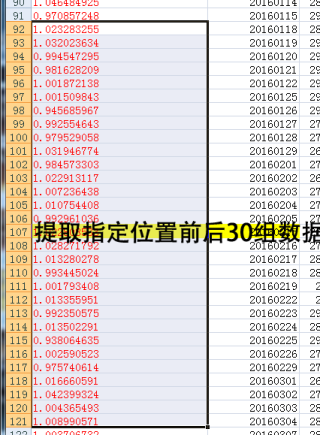

位置
107
344
602
836
1073
1328
import os
import pandas as pd
# 保存的文件名称
save_name = 'all.csv'
# 保存的路径
root = 'D:\\001'
# 读取文件
file_names ='99999.csv'
tableList = []
# 变量(107,344,602,836,1073,1328)
# 输出: 107前后15个 1.023283255 1.032023634 0.994547295 0.981628209 1.001872138 1.001509843 0.945685967 0.992554643 0.979529058 1.031946774 0.984573303 1.022913117 1.007236438 1.010754408 0.992961036 1.022808533 1.028271792 1.013280278 0.993445024 1.001793408 1.013355951 0.992350575 1.013502291 0.938064635 1.002590523 0.975740614 1.016660591 1.042399324 1.004365493 1.008990571
# 输出: 344前后15个 后续跟上面一样
finalData.to_csv(root + '\\' + save_name ,encoding="ANSI",index=False)
import pandas as pd
# 保存的文件名称
save_name = 'all.csv'
root = r'C:\Users\Lenovo\Desktop'
# 保存的路径
file_names = r'C:\Users\Lenovo\Desktop\99999.csv'
df = pd.read_csv(file_names, header=None)
finalData = pd.DataFrame(columns=[i + 1 for i in range(30)])
tableList = [107, 344]
for index in tableList:
if index - 15 > df.shape[0] or index + 14 <= 0: # 防止越界
print('Error:index %d overflow' % index)
continue
startIndex = index - 15
endIndex = index + 14
if startIndex <= 0:
startIndex = 1
if endIndex > df.shape[0]:
endIndex = df.shape[0]
finalData.loc['%d的30组数据' % index] = df[startIndex - 1: endIndex].values.T[0]
print(finalData)
finalData.to_csv(root + '\\' + save_name, encoding="ANSI", header=None)