pandas 统计多列中指定值的数量该怎么做?
我在网上查到的要么是需要groupby,要么是只能单列统计,就没有一下统计整张表的做法
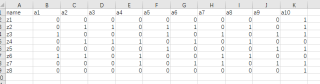
像这样一张表,我想统计每列有几个1
不需要用name分组啥的
就直接输出
a1 a2 .......a9
2 3 3
这样有没有办法?
从网上摸到做法了,运气真好
(df==value).sum()
直接data.sum()
不想要第一列就提出来再sum()

如果不固定,那用groupby 或者sum()解决不了

我写了个例子,供参考。
import pandas as pd
from random import randint
data_list = []
row_len = 5
for j in range(row_len):
d = ['name{}'.format(j)]
d.extend([randint(0,2) for i in range(11)])
data_list.append(d)
df1 = pd.DataFrame(data_list)
col_name =['name']
col_name.extend(['a{}'.format(i) for i in range(11)])
df1.columns = col_name
print("数据:")
print(df1)
print("数据sum():")
print(df1.sum())
print("遍历所有1:")
for i in range(1,11):
fld = 'a{}'.format(i)
df2 = df1[fld][df1[fld]==1]
# print(df2)
print(fld,len(df2))