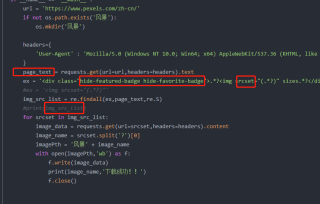
爬虫只得到空列表怎么解决#print(img_src_list)
问题遇到的现象和发生背景
问题相关代码,请勿粘贴截图
运行结果及报错内容
我的解答思路和尝试过的方法
我想要达到的结果
import requests
import re
import os
if __name__ == '__main__':
url = 'https://www.pexels.com/zh-cn/'
if not os.path.exists('风景'):
os.mkdir('风景')
headers={
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36 Edg/97.0.1072.69'
}
page_text = requests.get(url=url,headers=headers).text
ex = '<div class="hide-featured-badge hide-favorite-badge">.*?<img srcset="(.*?)" sizes.*?</div>'
#ex = '<img srcset="(.*?)"'
img_src_list = re.findall(ex,page_text,re.S)
#print(img_src_list)
for srcset in img_src_list:
image_data = requests.get(url=srcset,headers=headers).content
image_name = srcset.split('?')[0]
imagePth = '风景' + image_name
with open(imagePth,'wb') as f:
f.write(image_data)
print(image_name,'下载成功!!')
f.close()
此代码在print处只能得到空列表是为什么?
我测试了一下
page_text 没有 包含 “hide-featured-badge hide-favorite-badge” , “img srcset=” 相关的内容 , 导致 img_src_list 是空的。