一个python requests 爬虫遇到乱码的问题
我在爬虫的时候遇到了这样的乱码,太原本应该是中文
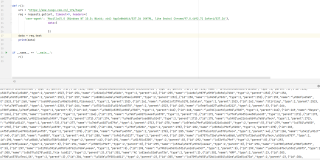
来看看这个是什么意思他出现的乱码都是些 \u5361 \u5206 的?
jsonData='{"\u6d4b\u8bd5": 12345, "\u5185\u5bb9": ["\u6211\u4e5f\u4e0d\u77e5\u9053\u6211\u8981\u5199\u4ec0\u4e48", "123"]}'
print(jsonData)
print(type(jsonData)) # <class 'str'> 理解为json字符串
py_type_info=json.loads(jsonData,ensure_ascii=false)
print(py_type_info)
print(type(py_type_info)) # <class 'dict'>
# 输出:
#{"测试": 12345, "内容": ["我也不知道我要写什么", "123"]}
# <class 'str'>
# {'测试': 12345, '内容': ['我也不知道我要写什么', '123']}
# <class 'dict'>
在requests.get后面加content.decode()解码,
requests.get().content.decode()
你试一下