在dataframe中,如何按多个列分组,对特定列按特定条件进行统计,并添加新的count列?
给定数据帧df1如下:
Col1 Col2 Col3 Col4
-------------------------------------——————
A 2021/1/12 AA 1
A 2021/1/12 AA 1
D 2021/1/13 AA 1
A 2021/1/12 FF 0
B 2021/1/12 FF 0
C 2021/1/12 AA 4
C 2021/1/12 FF 1
C 2021/1/12 FF 0
D 2021/1/12 AA 0
我想按Col1、Col2进行分组,然后
添加新列计数:其中Col1、Col2条件下Col3为AA的个数,为为FF的个数
输出需求:
Col1 Col2 AA模式计数 FF模式计数
----------------------------------------
A 2021/1/12 2 1
B 2021/1/12 0 1
C 2021/1/12 1 2
D 2021/1/13 1 0
D 2021/1/12 0 1
看了你贴的数据了, 的确是数值型 , 改一下字典构造
import pandas as pd
# 初始化数据
data_str = '''Col1,Col2,Col3,Col4
A,2021/1/12,1,1
A,2021/1/12,1,1
D,2021/1/13,0,1
A,2021/1/12,0,0
B,2021/1/12,2,0
C,2021/1/12,3,4
C,2021/1/12,1,1
C,2021/1/12,1,0
D,2021/1/12,0,0'''
lst = [n.split(",") for n in data_str.split()]
for i in range(1,len(lst)):
lst[i][2] = int(lst[i][2])
for l in lst:
print(l)
df1 = pd.DataFrame(lst[1:])
df1.columns = lst[0]
df2 = df1.groupby(['Col1', 'Col2', 'Col3']).count()
# 处理过程
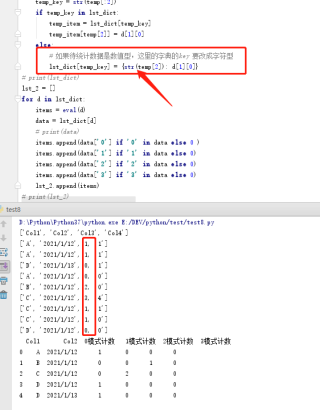
lst_dict = {}
for d in df2.iterrows():
temp = list(d[0])
temp_key = str(temp[:2])
if temp_key in lst_dict:
temp_item = lst_dict[temp_key]
temp_item[temp[2]] = d[1][0]
else:
# 如果待统计数据是数值型,这里的字典的key 要改成字符型
lst_dict[temp_key] = {str(temp[2]): d[1][0]}
# print(lst_dict)
lst_2 = []
for d in lst_dict:
items = eval(d)
data = lst_dict[d]
# print(data)
items.append(data['0'] if '0' in data else 0 )
items.append(data['1'] if '1' in data else 0)
items.append(data['2'] if '2' in data else 0)
items.append(data['3'] if '3' in data else 0)
lst_2.append(items)
# print(lst_2)
df3 = pd.DataFrame(lst_2)
df3.columns = ['Col1','Col2','0模式计数',' 1模式计数','2模式计数','3模式计数']
print(df3)
大概过程如下
转成字典-列表-Dataframe
import pandas as pd
# 初始化数据
data_str = '''Col1,Col2,Col3,Col4
A,2021/1/12,AA,1
A,2021/1/12,AA,1
D,2021/1/13,AA,1
A,2021/1/12,FF,0
B,2021/1/12,FF,0
C,2021/1/12,AA,4
C,2021/1/12,FF,1
C,2021/1/12,FF,0
D,2021/1/12,AA,0'''
lst = [n.split(",") for n in data_str.split()]
df1 = pd.DataFrame(lst[1:])
df1.columns = lst[0]
df2 = df1.groupby(['Col1','Col2','Col3']).count()
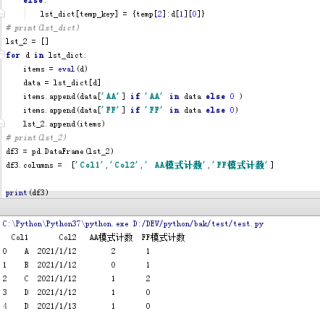
# 处理过程
lst_dict = {}
for d in df2.iterrows():
temp = list(d[0])
temp_key = str(temp[:2])
if temp_key in lst_dict:
temp_item = lst_dict[temp_key]
temp_item[temp[2]] = d[1][0]
else:
lst_dict[temp_key] = {temp[2]:d[1][0]}
# print(lst_dict)
lst_2 = []
for d in lst_dict:
items = eval(d)
data = lst_dict[d]
items.append(data['AA'] if 'AA' in data else 0 )
items.append(data['FF'] if 'FF' in data else 0)
lst_2.append(items)
# print(lst_2)
df3 = pd.DataFrame(lst_2)
df3.columns = ['Col1','Col2',' AA模式计数','FF模式计数']
print(df3)
那就改这段
lst_2 = []
for d in lst_dict:
items = eval(d)
data = lst_dict[d]
items.append(data['0'] if '0' in data else 0 )
items.append(data['1'] if '1' in data else 0)
items.append(data['2'] if '2' in data else 0)
items.append(data['3'] if '3' in data else 0)
lst_2.append(items)
# print(lst_2)
df3 = pd.DataFrame(lst_2)
df3.columns = ['Col1','Col2','0模式计数',' 1模式计数','2模式计数','3模式计数']
我想应该是你的数据格式问题, 如果是字符型,是没问题, 没统计到可能是数值型的缘故

import pandas as pd
# 初始化数据
data_str = '''Col1,Col2,Col3,Col4
A,2021/1/12,1,1
A,2021/1/12,1,1
D,2021/1/13,0,1
A,2021/1/12,0,0
B,2021/1/12,2,0
C,2021/1/12,3,4
C,2021/1/12,1,1
C,2021/1/12,1,0
D,2021/1/12,0,0'''
lst = [n.split(",") for n in data_str.split()]
df1 = pd.DataFrame(lst[1:])
df1.columns = lst[0]
df2 = df1.groupby(['Col1', 'Col2', 'Col3']).count()
# 处理过程
lst_dict = {}
for d in df2.iterrows():
temp = list(d[0])
temp_key = str(temp[:2])
if temp_key in lst_dict:
temp_item = lst_dict[temp_key]
temp_item[temp[2]] = d[1][0]
else:
lst_dict[temp_key] = {temp[2]: d[1][0]}
# print(lst_dict)
lst_2 = []
for d in lst_dict:
items = eval(d)
data = lst_dict[d]
items.append(data['0'] if '0' in data else 0 )
items.append(data['1'] if '1' in data else 0)
items.append(data['2'] if '2' in data else 0)
items.append(data['3'] if '3' in data else 0)
lst_2.append(items)
# print(lst_2)
df3 = pd.DataFrame(lst_2)
df3.columns = ['Col1','Col2','0模式计数',' 1模式计数','2模式计数','3模式计数']
print(df3)