新版知乎数据无法在浏览器中获取,如何解决?
问题说明: 无法通过RUL在浏览器中获取数据信息
这两天在学习爬虫,试着爬取知乎一个话题的讨论数据,找到数据的URL后,直接通过浏览器访问却没有返回数据。
话题链接: https://www.zhihu.com/topic/20086364/hot
数据URL:
https://www.zhihu.com/api/v5.1/topics/20086364/feeds/essence?offset=10&limit=10&include=data[?(target.type=topic_sticky_module)].target.data[?(target.type=answer)].target.content,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[?(target.type=topic_sticky_module)].target.data[?(target.type=answer)].target.is_normal,comment_count,voteup_count,content,relevant_info,excerpt.author.badge[?(type=best_answerer)].topics;data[?(target.type=topic_sticky_module)].target.data[?(target.type=article)].target.content,voteup_count,comment_count,voting,author.badge[?(type=best_answerer)].topics;data[?(target.type=topic_sticky_module)].target.data[?(target.type=people)].target.answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics;data[?(target.type=answer)].target.annotation_detail,content,hermes_label,is_labeled,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,answer_type;data[?(target.type=answer)].target.author.badge[?(type=best_answerer)].topics;data[?(target.type=answer)].target.paid_info;data[?(target.type=article)].target.annotation_detail,content,hermes_label,is_labeled,author.badge[?(type=best_answerer)].topics;data[?(target.type=question)].target.annotation_detail,comment_count;
在浏览器中复制粘贴上述URL,返回以下报错信息:
{
"error": {
"code": 10002,
"message": "10002:\u8bf7\u6c42\u53c2\u6570\u5f02\u5e38\uff0c\u8bf7\u5347\u7ea7\u5ba2\u6237\u7aef\u540e\u91cd\u8bd5"
}
}
在F12开发者模式中,是可以看到预览的数据信息

请哪位解惑,怎么能够拿到数据?
你是用requests抓取页面内容吧
可能是requests伪造的头部信息不全。
要在headers中添加抓包时的请求头求参数
headers={
'User-Agent': 'xxxxxxxxxxx',
'Host' : 'xxxxxxxxxxx',
'Origin' : 'xxxxxxxxxxxxx',
'Referer' : 'xxxxxxxxxxxxxx',
'Cookie': 'xxxxxxxxxxxxxxxx'
}
res = requests.get(url,headers=headers)
其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到
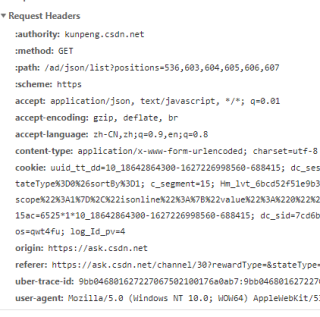
写代码请求网页数据时,针对数据链接,需要将标头,载荷和cookie的内容作为参数传递。
请问博主解决这个问题了吗?
请问博主后来解决这个问题了吗
应该是做了反爬,你加上请求头的各个参数和cookies试试