训练好的beta-VAE模型(效果很好)对于单张图片无法利用模型(权重)进行图片复原,如何解决?
模型已经训练好了,输入一个batch的数据能够利用模型的权重复原图片,如图所示:

但是如果采用单个图片,用模型编码到z值再解码效果很差。如图所示:
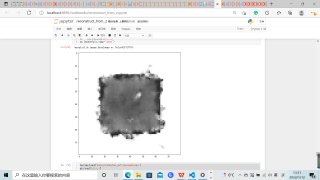
单个图片复原(未成功)使用的代码为:
#加载模型
with open('configs/bbvae_raven.yaml', 'r') as file:
config = yaml.safe_load(file)
#data = VAEDataset(**config["data_params"], pin_memory=len(config['trainer_params']['gpus']) != 0)
model = vae_models[config['model_params']['name']](**config['model_params'])
state_dict=torch.load('logs/BetaVAE/version_46/checkpoints/epoch=149-step=60599.ckpt')
state_dict=state_dict['state_dict']
from collections import OrderedDict
new_state_dict=OrderedDict()
for k,v in state_dict.items():
name=k[6:]
new_state_dict[name]=v
model.load_state_dict(new_state_dict)
#利用模型将图片encode到z值
from torchvision import transforms
def forward_to_z(input: Tensor, **kwargs) -> Tensor:
mu, log_var = model.encode(input)
z = model.reparameterize(mu, log_var)
#print(self.decode(z).size())
return z
img_tensor=transforms.functional.to_tensor(img) #将图片输入tensor
z=forward_to_z(img_tensor.reshape(1,1,80,80))#利用模型权重获取z值
#利用z值复原图片
recons=model.decode(z)
pic=recons.detach().numpy()[0,0,:,:]
一个batch的图片复原(成功)使用的代码为:
#加载模型
with open('configs/bbvae_raven.yaml', 'r') as file:
config = yaml.safe_load(file)
#data = VAEDataset(**config["data_params"], pin_memory=len(config['trainer_params']['gpus']) != 0)
model = vae_models[config['model_params']['name']](**config['model_params'])
state_dict=torch.load('logs/BetaVAE/version_46/checkpoints/epoch=149-step=60599.ckpt')
state_dict=state_dict['state_dict']
from collections import OrderedDict
new_state_dict=OrderedDict()
for k,v in state_dict.items():
name=k[6:]
new_state_dict[name]=v
model.load_state_dict(new_state_dict)
#使用Dataloader生成1个brach的图片
data = RAVENDataset(**config["data_params"], pin_memory=len(config['trainer_params']['gpus']) != 0)
data.setup()
experiment = VAEXperiment(model,
config['exp_params'])
test_input, test_label = next(iter(RAVENDataset.test_dataloader(data)))
# test_input, test_label = next(iter(self.trainer.datamodule.test_dataloader()))
test_input = test_input.to(experiment.curr_device)
test_label = test_label.to(experiment.curr_device)
#将图片encode到z值
def forward_to_z(input: Tensor, **kwargs) -> Tensor:
mu, log_var = model.encode(input)
z = model.reparameterize(mu, log_var)
#print(self.decode(z).size())
return z
z=forward_to_z(test_input)
# # recons=model.decode(z)
np.save('Data/twobytwo_out/zz.npy',z.detach().numpy())
#从z值decode到图片
recons=model.decode(z)
np.save('Data/twobytwo_out/reconss.npy',recons.detach().numpy())
其中model.encode和model.decode为beta-VAE模型的encode和decode。
另外,在gpu上load模型,进行转化并还原图片效果很好,将z值储存并下载到自己的电脑上以后使用同样的模型和model.decode代码无法还原图片。
而且当调整dataloader一个brach只包含1个图片的时候还原效果也非常不好。
而且通过model.forward计算出的mu值在自己电脑上和在gpu上结果不一样。程序没有随机的因素在里面。如果权重一样不是应该相等吗?不知道为什么会有差异。
我希望能通过模型得到能decode得到清晰图片的稳定z值。能不能帮忙看下问题出在哪呢?谢谢了!
你好,我是有问必答小助手,非常抱歉,本次您提出的有问必答问题,技术专家团超时未为您做出解答
本次提问扣除的有问必答次数,已经为您补发到账户,我们后续会持续优化,扩大我们的服务范围,为您带来更好地服务。