代码运行错误:AttributeError: 'NoneType' object has no attribute 'find'
问题遇到的现象和发生背景 :代码运行报错:AttributeError: 'NoneType' object has no attribute 'find'
问题相关代码,请勿粘贴截图 :
import requests
from bs4 import BeautifulSoup
import pprint
import json
def download_all_htmls():
htmls=[]
for idx in range(40):
url=f"http://www.crazyant.net/page/{idx+1}"
print("craw html:",url)
r=requests.get(url)
if r.status_code!=200:
raise Exception("error")
htmls.append(r.text)
return htmls
htmls=download_all_htmls()
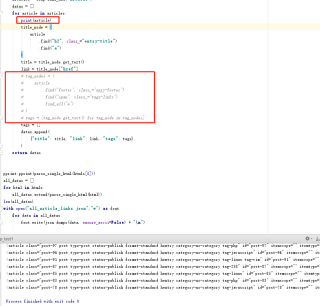
def parse_single_html(html):
soup =BeautifulSoup(html,'html.parser')
articles=soup.find_all("article")
datas=[]
for article in articles:
title_node=(
article
.find("h2",class_="entry-title")
.find("a")
)
title=title_node.get_text()
link=title_node["href"]
tag_nodes=(
article
.find("footer",class_="enry-footer")
.find("span",class_="tags-links")
.find_all("a")
)
tags=[tag_node.get_text() for tag_node in tag_nodes]
datas.append(
{"title":title,"link":link,"tags":tags}
)
return datas
pprint.pprint(parse_single_html(htmls[0]))
all_datas=[]
for html in htmls:
all_datas.extend(parse_single_html(html))
len(all_datas)
with open("all_article_links.json""w") as fout:
for data in all_datas:
fout.write(json.dumps(data, ensure_ascii=False) + "\n")
运行结果及报错内容 :
Traceback (most recent call last):
File "C:\Users\Administrator\Desktop\test\yuyue.py", line 39, in <module>
pprint.pprint(parse_single_html(htmls[0]))
File "C:\Users\Administrator\Desktop\test\yuyue.py", line 29, in parse_single_html
article
AttributeError: 'NoneType' object has no attribute 'find'
进程已结束,退出代码1
我想要达到的结果:代码运行正常
我发现你采集的数据 里 没有 class_="enry-footer" 和 class_="tags-links" 的内容
注释掉了,就正常运行了
你检查一下这两个关键字 ,改成正确的内容
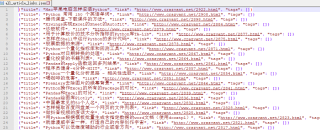
应该是
articles=soup.find_all("article")
这个地方返回了None
可以print(articles) 看看
然后改下代码,在使用前先判断是不是None
for article in articles:
if article:
# 你原先的代码