爬取下来的网页命名为wb_data,为什么wb_data.text与网页源代码内容不一样?
问题如题,我是小白,我看视频里面老师通过‘检查元素’定位元素在源代码中的位置,然后根据代码标签写selector,写代码,一运行就能得到想要的标签元素。我照着模仿,为什么结果为空,我最后发现我的wb_data.text与网页源代码有差别,我就想知道,为什么不一样?为什么视频中老师好像不会有这样的问题?下面是我的过程。
1. 我先打开要爬取的网页
2. 找到目标,点击检查元素定位其在网页代码中的位置
3. 观察,写selector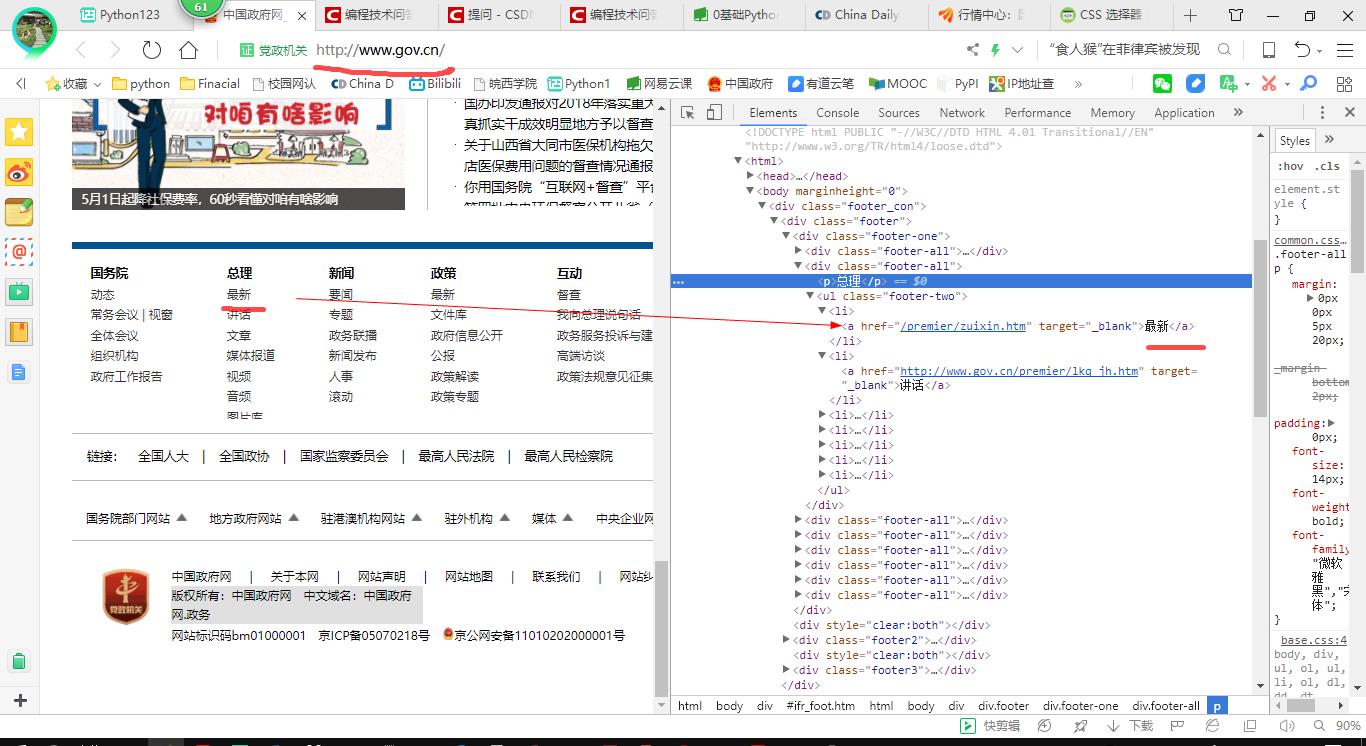
- 写代码
from bs4 import BeautifulSoup
import requests
url = 'http://www.gov.cn/'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, 'lxml')
title = soup.select('div.footer-all > ul.footer-two > li > a')
print(title)
最后结果:
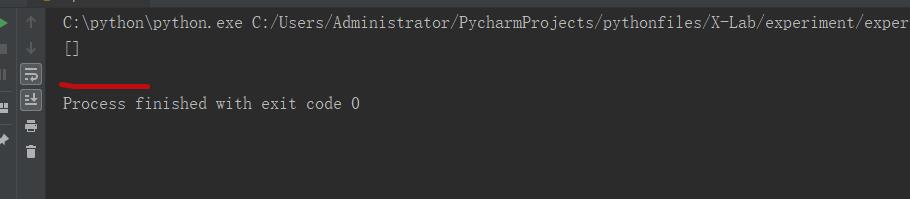
希望有大佬帮忙解答下,谢谢。
import requests
import re
from lxml import etree
url = 'http://www.gov.cn/'
wb_data = requests.get(url)
title = ''.join(re.findall(r'(.*)',wb_data.content.decode('utf-8')))
print(title)