python爬虫QQ音乐评论爬不了
问题相关代码
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'referer': 'https://y.qq.com/'
}
params={
"_":"1640602806807",
"sign":"zzb5d358b9cijwfbbdeg6mvuuvobby3ww678bc920"
}
res = requests.get(
'https://u.y.qq.com/cgi-bin/musics.fcg',
params=params,
headers=headers)
json_data=res.json()
print(json_data)
#这接下的步骤都运行不了,因为没有req_1的内容
#Comments=json_data['req_1']['data']['CommentList']['Comments']
#for i in Comments:
# print("用户:",i['Nick'])
print("评论:",i['Content'])
**运行结果及报错内容 **
{'code': 500001, 'ts': 1640611844715, 'start_ts': 1640611844715, 'traceid': '1ce1b4b5d0b7558e'}
如果把最后四行前面的#号删掉:
Traceback (most recent call last):
File "D:\pycharm\pythonProject\douban\QQ.py", line 21, in
Comments=json_data['req_1']['data']['CommentList']['Comments']
KeyError: 'req_1'
{'code': 500001, 'ts': 1640611929139, 'start_ts': 1640611929139, 'traceid': '2ea1507a5f31acab'}
不知道怎么办
https://u.y.qq.com/cgi-bin/musics.fcg 这个接口是post请求的,不是get请求,并且缺少了post的数据,headers可不配置也能获取数据,主要是post发送的数据和url参数上的数据不能少
下面测试正常

import requests
headers = {
#'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
#'referer': 'https://y.qq.com/',
#'referer': 'https://y.qq.com/n/ryqq/albumDetail/004cQkQ81Hbpw3'
}
data='{"comm":{"cv":4747474,"ct":24,"format":"json","inCharset":"utf-8","outCharset":"utf-8","notice":0,"platform":"yqq.json","needNewCode":1,"uin":0,"g_tk_new_20200303":5381,"g_tk":5381},"req_1":{"method":"GetCommentCount","module":"GlobalComment.GlobalCommentReadServer","param":{"request_list":[{"biz_type":2,"biz_id":"24323270"}]}},"req_2":{"module":"music.globalComment.CommentReadServer","method":"GetNewCommentList","param":{"BizType":2,"BizId":"24323270","LastCommentSeqNo":"","PageSize":25,"PageNum":0,"FromCommentId":"","WithHot":1}},"req_3":{"module":"music.globalComment.CommentReadServer","method":"GetHotCommentList","param":{"BizType":2,"BizId":"24323270","LastCommentSeqNo":"","PageSize":15,"PageNum":0,"HotType":2,"WithAirborne":1}},"req_4":{"module":"yqq.WhiteListServer","method":"Pass","param":{}}}'
url='https://u.y.qq.com/cgi-bin/musics.fcg'
params={'_':'1640661151903','sign':'zzbba988418sjf1ktry048xvbv5c843ia6ba1ee67'}
res = requests.post(
url, params=params,
data=data,
headers=headers)
json_data=res.json()
#print(json_data)
Comments=json_data['req_2']['data']['CommentList']['Comments']
for i in Comments:
print("用户:",i['Nick'])
print("评论:",i['Content'])

有帮助或启发麻烦点下【采纳该答案】,谢谢~~
是因为返回的json字符串解析成字典后其中没有req_1字段,也就是没有获取到相应的评论内容等数据,所以用字典键取值会报错。
可能是requests伪造的头部信息不全。
要在headers中添加抓包时的请求头求参数
headers={
'User-Agent': 'xxxxxxxxxxx',
'Host' : 'xxxxxxxxxxx',
'Origin' : 'xxxxxxxxxxxxx',
'Referer' : 'xxxxxxxxxxxxxx',
'Cookie': 'xxxxxxxxxxxxxxxx'
}
res = requests.get(url,headers=headers)
其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到
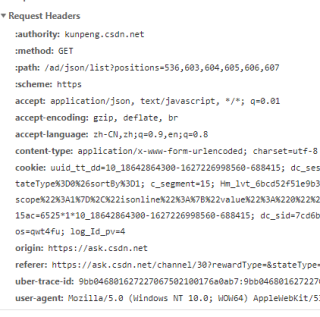
不仅headers要加cookie之类,在params中的时间戳也要伪造哦!