keras实现人脸识别,训练失败……请教大神指点迷津!!!
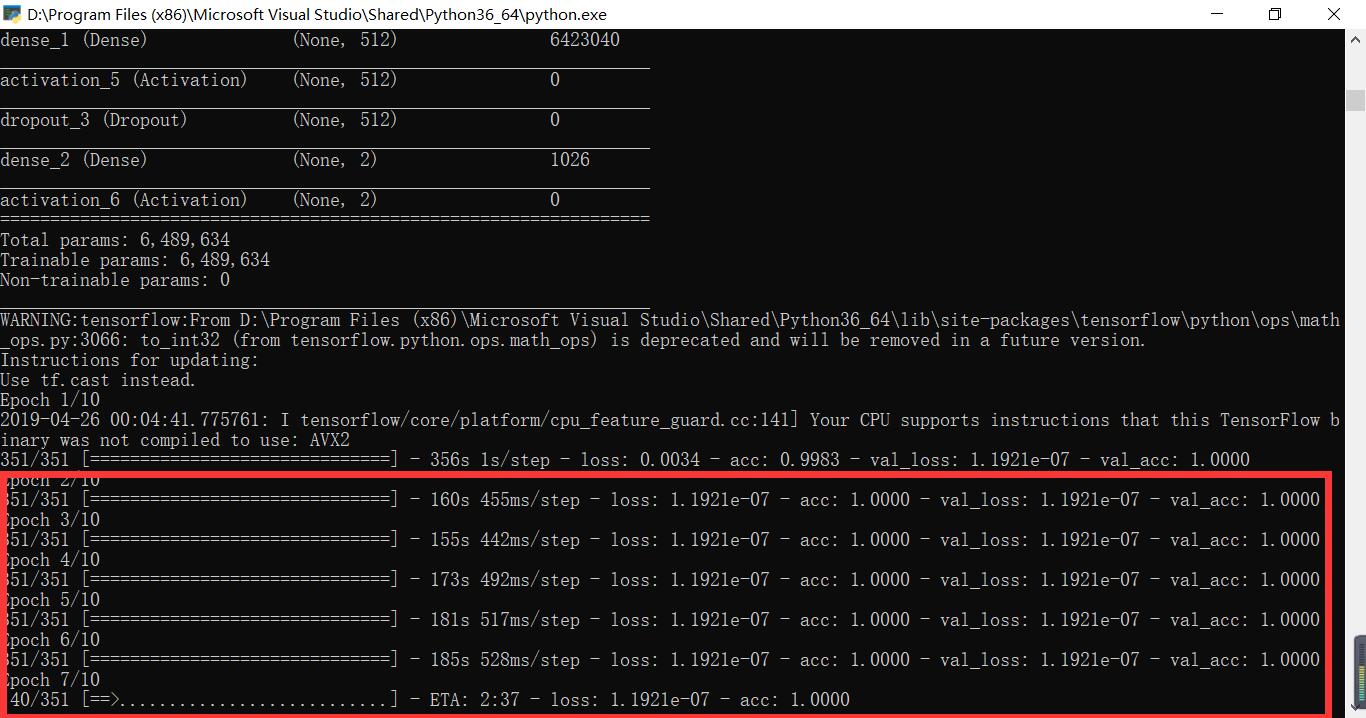
各位大神,如图所示,在训练过程中,第二轮开始出现问题,这是什么原因呢?
代码如下:
import random
import keras
import numpy as np
import cv2
from sklearn.model_selection import train_test_split
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import SGD
from keras.utils import np_utils
from keras.models import load_model
from keras import backend as K
from source_data import load_dataset,resize_img
#定义数据集格式
class Dataset:
def __init__(self, path_name):
#训练数据集
self.train_images = None
self.train_labels = None
#测试集
self.valid_images = None
self.valid_labels = None
#样本数据
self.test_images = None
self.test_labels = None
#load路径
self.path_name = path_name
#维度顺序
self.input_shape = None
#加载数据集并按照交叉验证的原则划分数据集,完成数据预处理
def load(self,img_rows=64, img_cols=64,img_channels = 3,nb_classes = 2):
#加载数据集到内存
images,labels=load_dataset(self.path_name)#函数调用
train_images, valid_images, train_labels, valid_labels= train_test_split(images, labels, test_size = 0.3, random_state = random.randint(0, 100))
_, test_images, _, test_labels = train_test_split(images, labels, test_size = 0.5, random_state = random.randint(0, 100))
#根据backend类型确定输入图片数据时的顺序为:channels,rows,cols,否则:rows,cols,channels
#这部分代码就是根据keras库要求的维度顺序重组训练数据集
train_images = train_images.reshape(train_images.shape[0], img_rows, img_cols, img_channels)
valid_images = valid_images.reshape(valid_images.shape[0], img_rows, img_cols, img_channels)
test_images = test_images.reshape(test_images.shape[0], img_rows, img_cols, img_channels)
self.input_shape = (img_rows, img_cols, img_channels)
#输出训练集、验证集、测试集的数量
print(train_images.shape[0], 'train samples')
print(valid_images.shape[0], 'valid samples')
print(test_images.shape[0], 'test samples')
#我们的模型使用categorical_crossentropy作为损失函数,因此需要根据类别数量nb_classes将
#类别标签进行one-hot编码使其向量化,在这里我们的类别只有两种,经过转化后标签数据变为二维
train_labels = np_utils.to_categorical(train_labels, nb_classes)
valid_labels = np_utils.to_categorical(valid_labels, nb_classes)
test_labels = np_utils.to_categorical(test_labels, nb_classes)
#像素数据浮点化以便归一化
train_images = train_images.astype('float32')
valid_images = valid_images.astype('float32')
test_images = test_images.astype('float32')
#将其归一化,图像的各像素值归一化到0—1区间
train_images /= 255
valid_images /= 255
test_images /= 255
self.train_images = train_images
self.valid_images = valid_images
self.test_images = test_images
self.train_labels = train_labels
self.valid_labels = valid_labels
self.test_labels = test_labels
class Model:
def __init__(self):
self.model = None
#建立keras模型
def build_model(self, dataset, nb_classes = 2):
#构建一个空的网络模型,序贯模型或线性堆叠模型,添加各个layer
self.model = Sequential()
#以下代码将顺序添加CNN网络需要的各层,一个add就是一个网络层
self.model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape = dataset.input_shape)) #1 2维卷积层
self.model.add(Activation('relu')) #2 激活函数层
self.model.add(Convolution2D(32, 3, 3)) #3 2维卷积层
self.model.add(Activation('relu')) #4 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) #5 池化层
self.model.add(Dropout(0.25)) #6 Dropout层
self.model.add(Convolution2D(64, 3, 3, border_mode='same')) #7 2维卷积层
self.model.add(Activation('relu')) #8 激活函数层
self.model.add(Convolution2D(64, 3, 3)) #9 2维卷积层
self.model.add(Activation('relu')) #10 激活函数层
self.model.add(MaxPooling2D(pool_size=(2, 2))) #11 池化层
self.model.add(Dropout(0.25)) #12 Dropout层
self.model.add(Flatten()) #13 Flatten层
self.model.add(Dense(512)) #14 Dense层,又被称作全连接层
self.model.add(Activation('relu')) #15 激活函数层
self.model.add(Dropout(0.5)) #16 Dropout层
self.model.add(Dense(nb_classes)) #17 Dense层
self.model.add(Activation('softmax')) #18 分类层,输出最终结果
#Prints a string summary of the network
self.model.summary()
#训练模型
def train(self, dataset, batch_size = 20, nb_epoch = 10, data_augmentation = True):
sgd = SGD(lr = 0.01, decay = 1e-6, momentum = 0.9, nesterov = True) #采用随机梯度下降优化器进行训练,首先生成一个优化器对象
self.model.compile(loss='categorical_crossentropy', optimizer=sgd,metrics=['accuracy']) #完成实际的模型配置
#不使用数据提升,所谓的提升就是从我们提供的训练数据中利用旋转、翻转、加噪声等方法提升训练数据规模,增加模型训练量
if not data_augmentation:
self.model.fit(dataset.train_images,
dataset.train_labels,
batch_size = batch_size,
epochs = nb_epoch,
validation_data = (dataset.valid_images, dataset.valid_labels),
shuffle = True)
#使用实时数据提升
else:
#定义数据生成器用于数据提升,其返回一个生成器对象datagen,datagen每被调用一
#次其生成一组数据(顺序生成),节省内存,其实就是python的数据生成器
datagen = ImageDataGenerator(
featurewise_center = False, #是否使输入数据去中心化(均值为0),
samplewise_center = False, #是否使输入数据的每个样本均值为0
featurewise_std_normalization = False, #是否数据标准化(输入数据除以数据集的标准差)
samplewise_std_normalization = False, #是否将每个样本数据除以自身的标准差
zca_whitening = False, #是否对输入数据施以ZCA白化
rotation_range = 20, #数据提升时图片随机转动的角度(范围为0~180)
width_shift_range = 0.2, #数据提升时图片水平偏移的幅度(单位为图片宽度的占比,0~1之间的浮点数)
height_shift_range = 0.2, #同上,只不过这里是垂直
horizontal_flip = True, #是否进行随机水平翻转
vertical_flip = False) #是否进行随机垂直翻转
#计算整个训练样本集的数量以用于特征值归一化等处理
datagen.fit(dataset.train_images)
#利用生成器开始训练模型—0.7*N
self.model.fit_generator(datagen.flow(dataset.train_images, dataset.train_labels,
batch_size = batch_size),
steps_per_epoch = dataset.train_images.shape[0],
epochs = nb_epoch,
validation_data = (dataset.valid_images, dataset.valid_labels))
if __name__ == '__main__':
dataset = Dataset('e:\saving')
dataset.load()#实例操作,完成实际数据加载和预处理
model = Model()
model.build_model(dataset)
#训练数据
model.train(dataset)
- 关于该问题,我找了一篇非常好的博客,你可以看看是否有帮助,链接:基于Keras的人脸识别
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 以帮助更多的人 ^-^